汇编
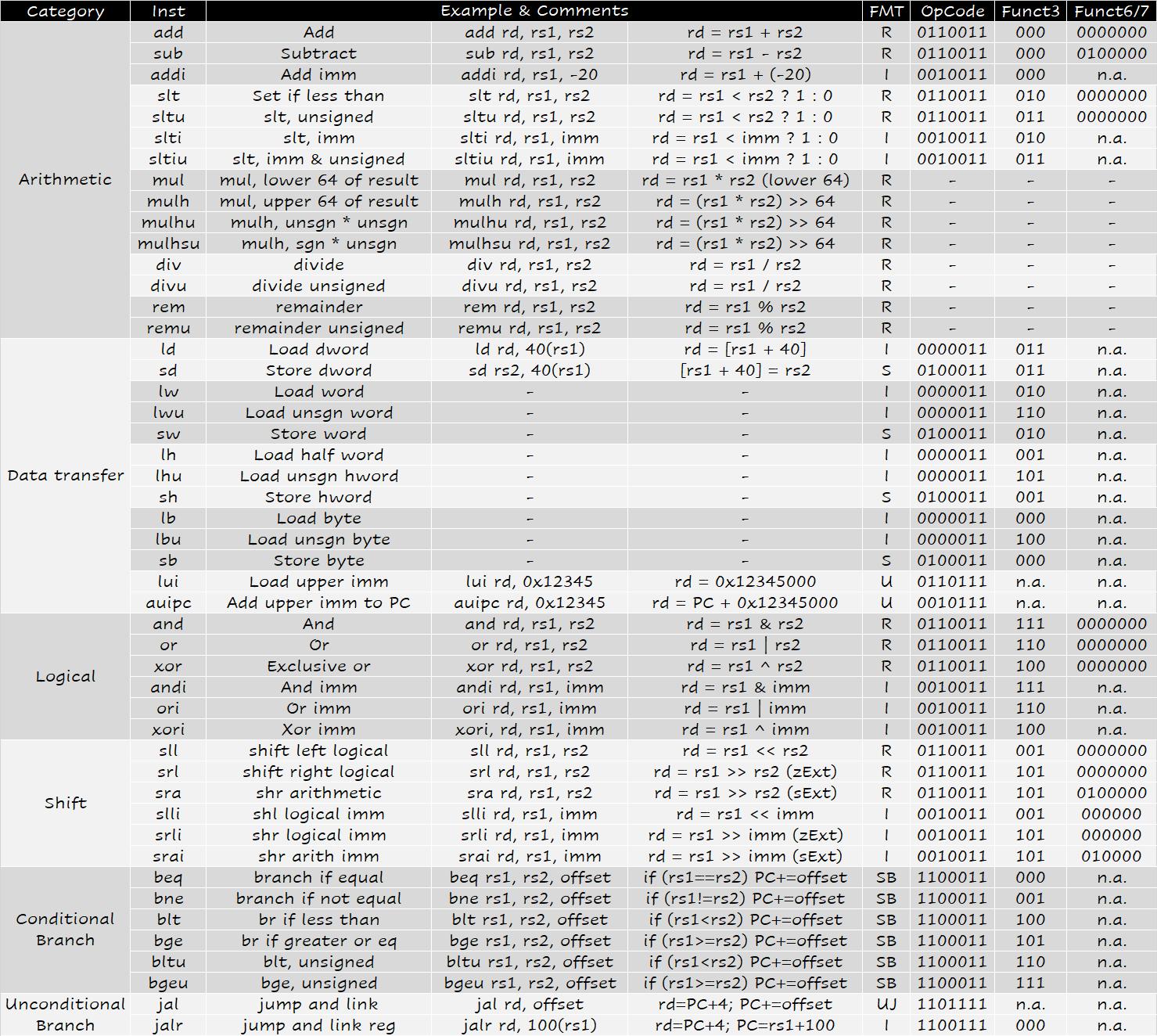
寄存器
32个64位寄存器 x0-x31
-
x0 (zero)是0 -
x1 (ra)是在jal,jalr时暂时存储PC的。执行ret的时候回到当前指令的下一条(PC+4) 注意和LC3\x86不同, RISC-V的PC指向的是当前指令 -
x2 (sp)是栈指针 -
x10是函数调用第一个参数 同时也是返回值 -
x10-x17是函数参数 -
x5-x7,x28-x31不保证调用前后不变 -
x9,x18-x27需要保证调用前后不变。 如果callee要用,必须保存一份,返回时恢复
内存
-
**word:32位 dword: 64位 **
ld是dword 64位lw是32位lh:16lbL8 -
RISC-V 地址64位,地址为字节地址. 因此在用reg+imm寻址时, 每个word就要地址+4, dword +8
-
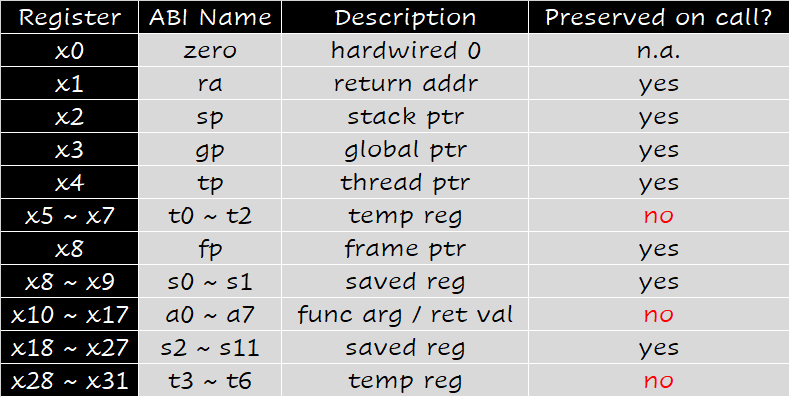
小端编码
- 将不足64位的数据载入寄存器, 如果是有符号数,要在前面填充符号位(如负数要全部填1). 无符号数填充0 在指令中的
lw,lh,lb使用 sign extension,而lwu,lhu,lbu使用 zero extension
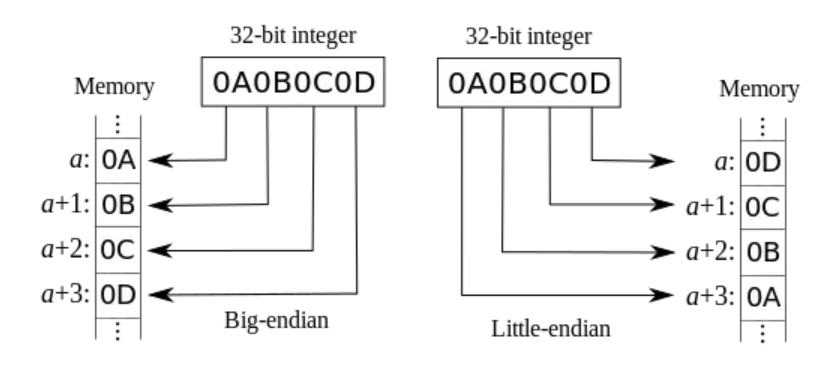
ALU
-
Set if less than
slt rd,rs1,rs2代表rd=rs1<rs2?1:0(slt有符号,sltu无符号) -
左移
sll rd,rs1,rs2代表rd=rs1<<rs2 - 右移
srl
分支
bltbranch if less thanbgebranch if greater or equal
跳转(jal,jalr)
jal rd,offsetrd=PC+4,PC+=offset一般用x1存储原来的下一条地址jal x1,funjalr rd,100(rs1)rd=PC+4,PC=rs1+100让PC返回x1中存储的地址用jalr x0,0(x1)(伪指令ret)
汇编转二进制
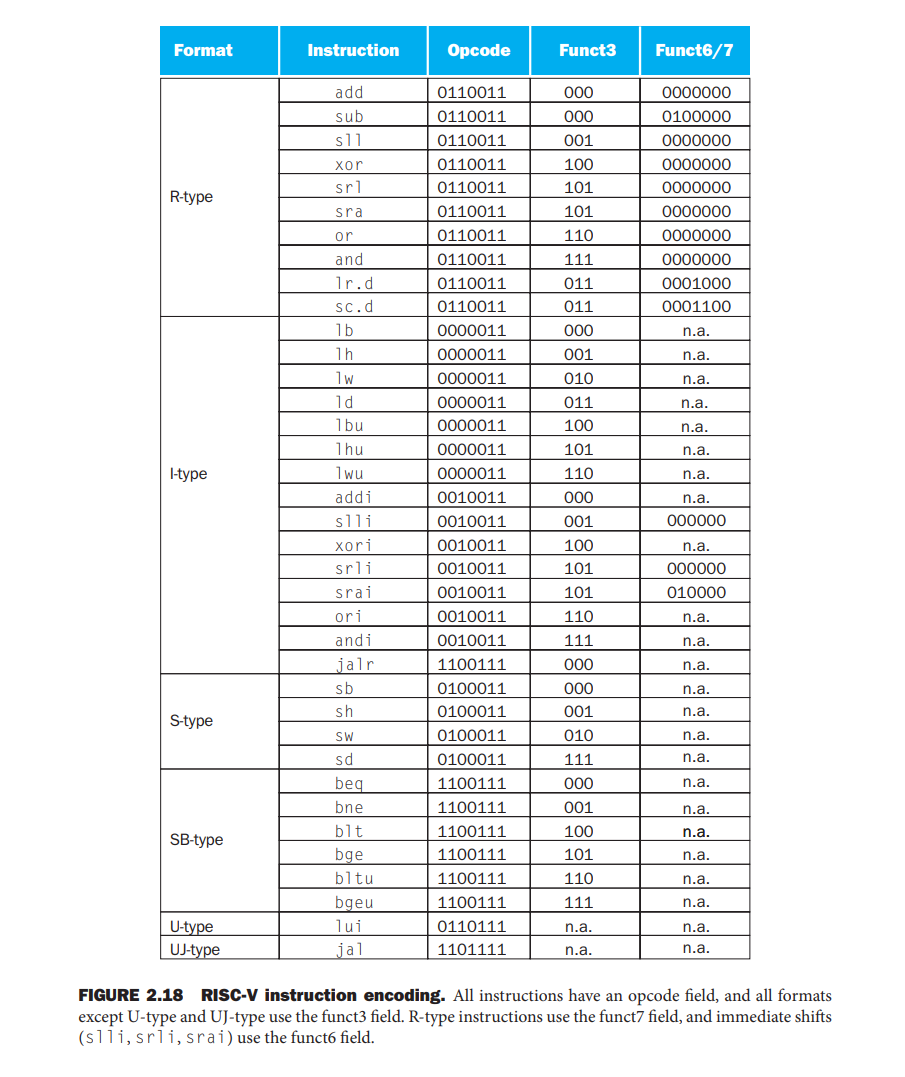
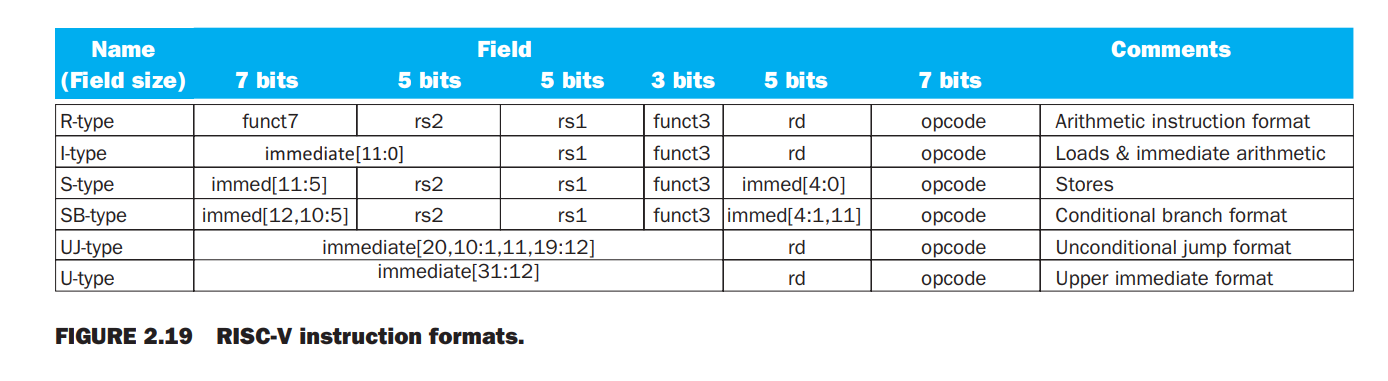
2.12 #2.14
- 注意rs2在rs1前面
- SB和UJ没有最低位
jal和beq的跳转范围
注意指令里没有立即数的最后1位,默认补0,所以跳转的总是偶数
- jal立即数\(i[20:1]\) ,21位补码, 原本的范围是\([-2^{20},2^{20}-1]\), 因为2字节,所以范围是\([-2^{20},2^{20}-2]=[\text{PC-0x100000},\text{PC+0xFFFFE}]\)
- beq
i[12:1]13位补码
大立即数
lui rd,imm 将 20 位常数加载到目标寄存器的 31 到 12 位;然后用 addi 填充后面 12 位,就可以实现加载32位大立即数。但是,如果后 12 位的首位是 1,在 addi 的时候就会因为 sign ext 额外加上 0xFFFFF000 。因此,我们只需要将 lui 的 imm 增加 1,这样 lui 加载后实际上就是增加了 0x00001000 ,和 0xFFFFF000 相加后就可以抵消影响了。
跳转到大地址
先lui
再jalr
汇编实现算法
分支和循环
注意循环越界条件判断一般用bge。如果考虑负数, a<0或a>=n可以用 bgeu x5,x20,1 (假设a是x5,n是x20)
while
无条件跳转goto LABEL 实现: bne x0,x0,LABEL
switch
会生成branch address tatble . 用jalr
Compiling a switch using jump address table ( Assume: f ~ k --x20 ~ x25 x5 contains 4/8)
switch ( k ) {
case 0 : f = i + j ; break ;
case 1 : f = g + h ; break ;
case 2 : f = g - h ; break ;
case 3 : f = i - j ; break ;
}
# x6是jump address table的起始地址
blt x25, x0, Exit # test if k < 0
bge x25, x5, Exit # if k >= 4, go to Exit
slli x7, x25, 3 # temp reg x7 = 8 * k
add x7, x7, x6 # x7 = address of JumpTable[k]
ld x7, 0(x7) # temp reg x7 gets JumpTable[k]
jalr x1, 0(x7) # jump based on register x7(entrance)
Exit:
A basic block is a sequence of instructions with
- No embedded branches (except at end)
- No branch targets/branch labels (except at beginning)
- Compiler optimize
过程调用和递归
过程调用 jal x1,fun: fun是label
栈: 从高地址往低地址
addi sp, sp, -24,sd x5, 16(sp),sd x6, 8(sp),sd x20, 0(sp)可以实现将 x5, x6, x20 压栈。x5-x7,x28-x31不保证调用前后不变x9,x18-x27需要保证调用前后不变。 如果callee要用,必须保存一份,返回时恢复
fact:
addi sp,sp,-16
sd ra,8(sp) #保存返回地址
sd x10,0(sp) #因为中间计算要用到参数n, x10不保证调用前后不变,所以caller save
addi x5,x10,-1 #x5是临时变量
bge x5,zero,L1 #n>=1
addi x10,x0,1 # n<1 return 1
addi sp,sp,16
jalr zero,0(ra)
L1:
addi x10,x10,-1
jal ra,fact # 调用fact(n-1)
add x5,x10,zero #x5暂时存储fact(n-1)的返回值x10
ld x10,0(sp) #取出前面存储的n x10=n
mul x10,x10,x5 #x10=fact(n-1)*n
ld ra,8(sp) #取出返回地址
add sp,sp,16 #还原栈
jalr zero,0(ra) #返回
32bit的写法 可在https://venus.cs61c.org/执行
addi x10,x0,3
jal ra,fact
fact:
addi sp,sp,-8
sw ra,4(sp) #保存返回地址
sw x10,0(sp) #因为中间计算要用到参数n, x10不保证调用前后不变,所以caller save
addi x5,x10,-1 #x5是临时变量
bge x5,zero,L1 #n>=1
addi x10,x0,1 # n<1 return 1
addi sp,sp,8
ret
L1:
addi x10,x10,-1
jal ra,fact # 调用fact(n-1)
add x5,x10,zero #x5暂时存储fact(n-1)的返回值x10
lw x10,0(sp) #取出前面存储的n x10=n
mul x10,x10,x5 #x10=fact(n-1)*n
lw ra,4(sp) #取出返回地址
addi sp,sp,8 #还原栈
ret