5 Memory
24-5-08 (两种cache cache performance)
24-5-13(page table) 24-5-15(期中)
Cache
Block Placement
1个word 是4 byte. Cache的大小是若干KB,一个block是若干word. 得到block个数n。
Direct mapped cache
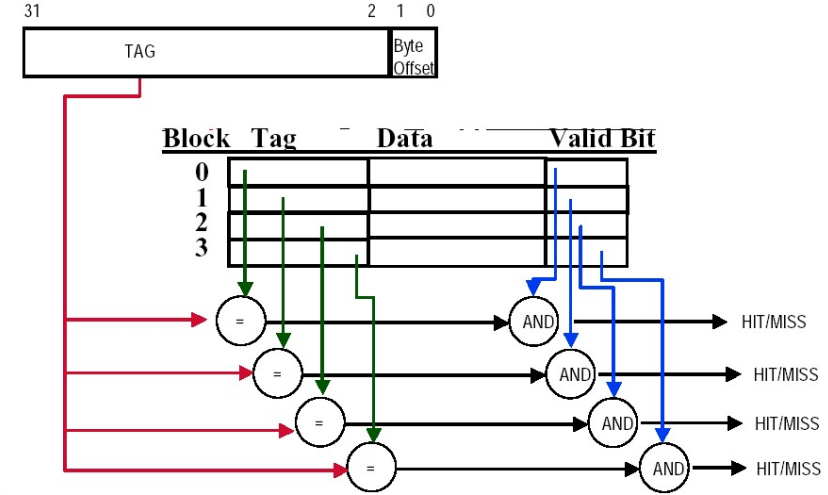
假设缓存有\(2^n\)个block, block size是\(2^k\)个 word 内存address是m位(默认是byte address)
- index: \(\log_2(\text{\#block})\)
- byte offset: \(\log_2(\text{block bytes})\) 比如说下面是4-word block, 对应16个bytes, 所以byte offset=4
- tag: \(m-\text{index}-\text{byte\_offset}\) 位
- valid bit: 1位
- data bits: \(2^k\times 32=2^{k+5}\) (一个words 32 bit)
总大小是\(2^n(tag+data+valid)\)

注意4-word block 对应16个byte, 所以需要4位来索引每个byte, tag 那里才需要-2-2

$$
\lfloor address/\text{bytes per block} \rfloor \bmod blocknum
$$
一个block里的address范围 因为16*75=1200

Fully associative
block可以去任何地方
Set associative
cache分为多个set, 内存里每个block对应的set是确定的,但是set内部可以任意放 . 每个set里面的block个数称为set associativity
index 就是用来确定放在哪个 set 中的。因此,index 的位数就对应着 set 的个数
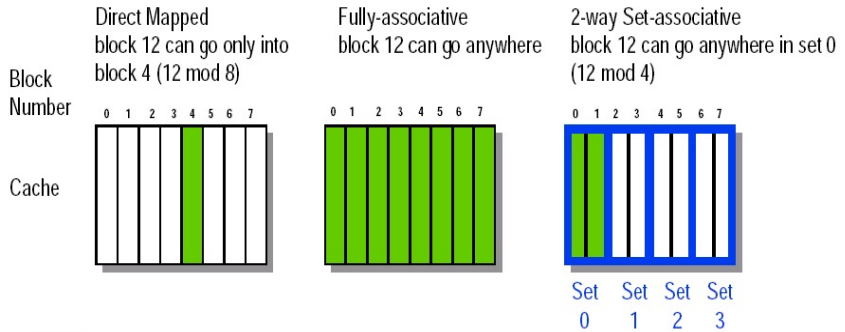
Directed map实际上就是1-way set , Fully-associative实际上就是n-way set
 miss rate比direct map低
miss rate比direct map低
set associativity对miss rate的影响
如果每个set里面只有1个block miss rate就会很高。 但是block多了, 找到对应的block就会很慢
Block Identification
怎么判断hit/miss
Direct mapped只需要找到内存地址对应的block,看下Tag是否跟当前地址对应
Fully associative: 每次要和所有block比较
Block replacement
DB也讲过
- Random replacement: 随机替换
- LRU: 选择上一次使用时间最早的替换
- FIFO: 选择进入时间最早的block替换
Write strategy
当cache里面的block被更新
- write through: 立刻把更改写到内存里
- write back: 不是立即写到内存里。 等到这个block要被覆盖掉的时候再写到内存里。 由于对同一个 block 通常会被多次写入,因此这种方式消耗的总带宽是更小的。
- 要加入dirty bits来标记是否被修改
- 使用write buffer
- 如果write miss,有两种方式 1)write allocate,即像 read miss 一样先把 block 拿到 cache 里再写入2)write around (or no write allocate),考虑到既然本来就要去一次 main memory,不如直接在里面写了,就不再拿到 cache 里了。
- write-back 只能使用 write allocate;一般来说,write-through 使用 write around,其原因是明显的。
Performance
Memory Width
假设内存宽度为1 word. cache block为4 word.
但是如果miss, 整个block都要更新。一共4个word,要访问内存4次。总时间是1+4(1+15)=65 带宽=16/65
但是如果增大内存宽度为2word, 就可以减少miss的时候访存次数. 总时间变为1+2(1+15) 带宽=33/65

Block size
增加block size, 减少miss rate
Mesuring Cache Performance
 如果CPI减少:
如果CPI减少:
 如果CPU时钟频率变快: 内存的速度是不变的,所以miss penalty 从100 cycle变到200 cycle 周期数需要重新计算
如果CPU时钟频率变快: 内存的速度是不变的,所以miss penalty 从100 cycle变到200 cycle 周期数需要重新计算

这说明内存的速度会拖慢CPU的性能提高