SQL
基本概念
数据类型:
varchar(n): 长度至多为n字节的字符串numeric(p,d)float(n)real,double,precision
DDL
创建表
A是属性名(attribute), D是相当于数据类型的值域(domain)
Integrity constr:
-
primary key: (注意自动限制not null的) -
unique -
not null -
foreign key (xxx) references table_y
Relation Algebra&SQL
关系代数: 输入和输出都是关系 (SQL中的表)
Select/Project/Cartesian Product
-
select: \(\sigma_p(r)=\{t|(t\in r) \wedge p(t)\}\) 筛选出满足条件\(p\)的所有
-
project: \(\prod_{a_1\dots a_n}(r)\) 原来的关系r中只保留属性\(a_1\dots a_n\)的列。在关系代数中,会自动去重
- 但在SQL里面,不会去重
-
cartesian product
where的用法:
字符串可用正则
from的用法 a1,a2,a3..., 表示笛卡尔积, 常常和select一起用,a.primary_key=b.foreign_key
select card.name,book.title,borrow.borrow_date
from book,card,borrow
where card.name='张三' and
card.cno=borrow.cno and
book.bno=borrow.bno
Rename
as 对表和属性进行重命名
找比某个CS老师工资高的老师
Set operation
A,B是两个select子句
- \(A\cup B\):
A union B - \(A-B\)
A except B - \(A\cap B\)
A intersect B
和select不一样,SQL集合运算会自动去重. 如果要不去重,要写成union all
Aggregate
- 对于关系中所有G1,G2...Gn值都相同的元素进行聚合
- 注意没有写在G前面和后面的属性会被去掉

having: 对聚合的结果做查询(这样就不用嵌套一个select)
group by a,b 可以添加多个,只有a,b都一样的才会被聚合到一起
Nested Query
where
where A in S 找出表中属性A的值在集合S中的元素(sql查询结果)

some: 只要在集合中存在一个满足条件,就返回true \(5 \neq some \{0,5\}\)

all: 全部满足条件 exists: 不需要指定列,只需要判断前面空/不空

not exist:
 其实都可以用笛卡尔积写,但不直观
其实都可以用笛卡尔积写,但不直观
from
可以不用having
With
定义一个子表(只能在当前查询里面用)
Null Value
where a is null用来查询null, 不能写=null- 任意数和null的算术运算返回null
- 任意数和null的逻辑运算返回unknown
- 除了
count(*)之外的聚合操作如sum,avg忽略null
Join
The join operation allows us to combine a select operation and a Cartesian-Product operation into a single operation
Natural join 自然连接
- 同名属性被当作同一个属性
- 如果同名意义不同如
course.name,stu.name就不能natural join.
- sql server不支持natural join语法
Outer-Join:
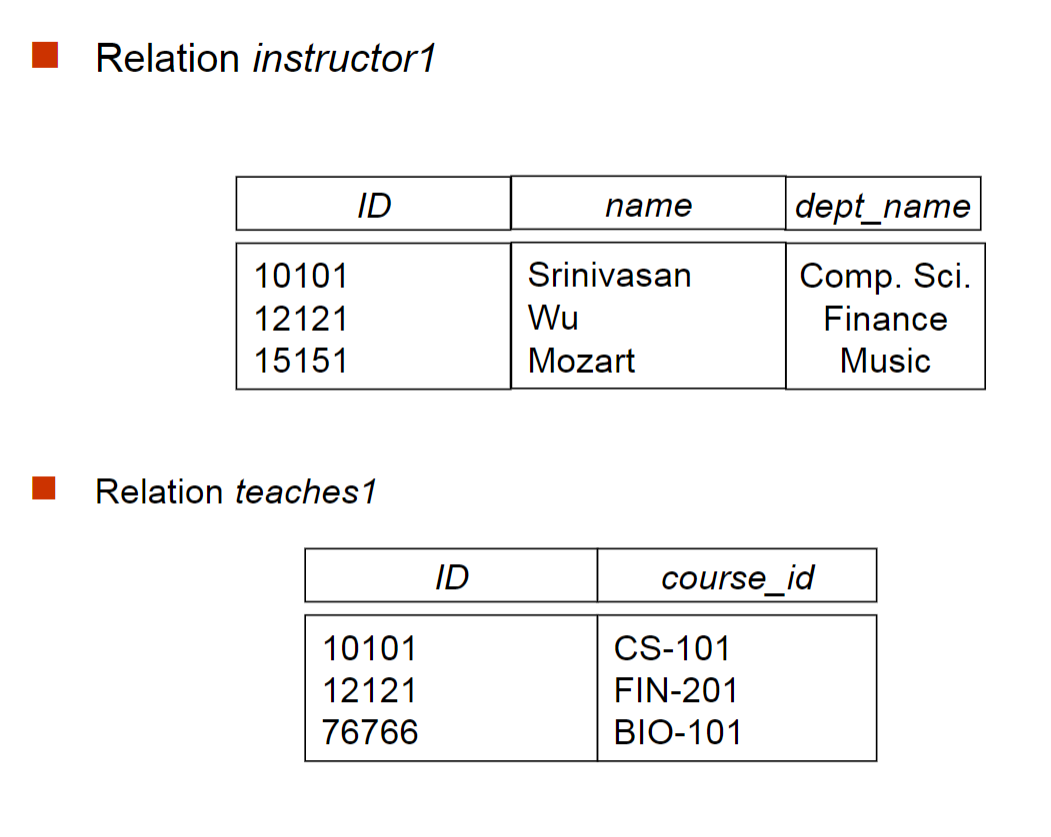
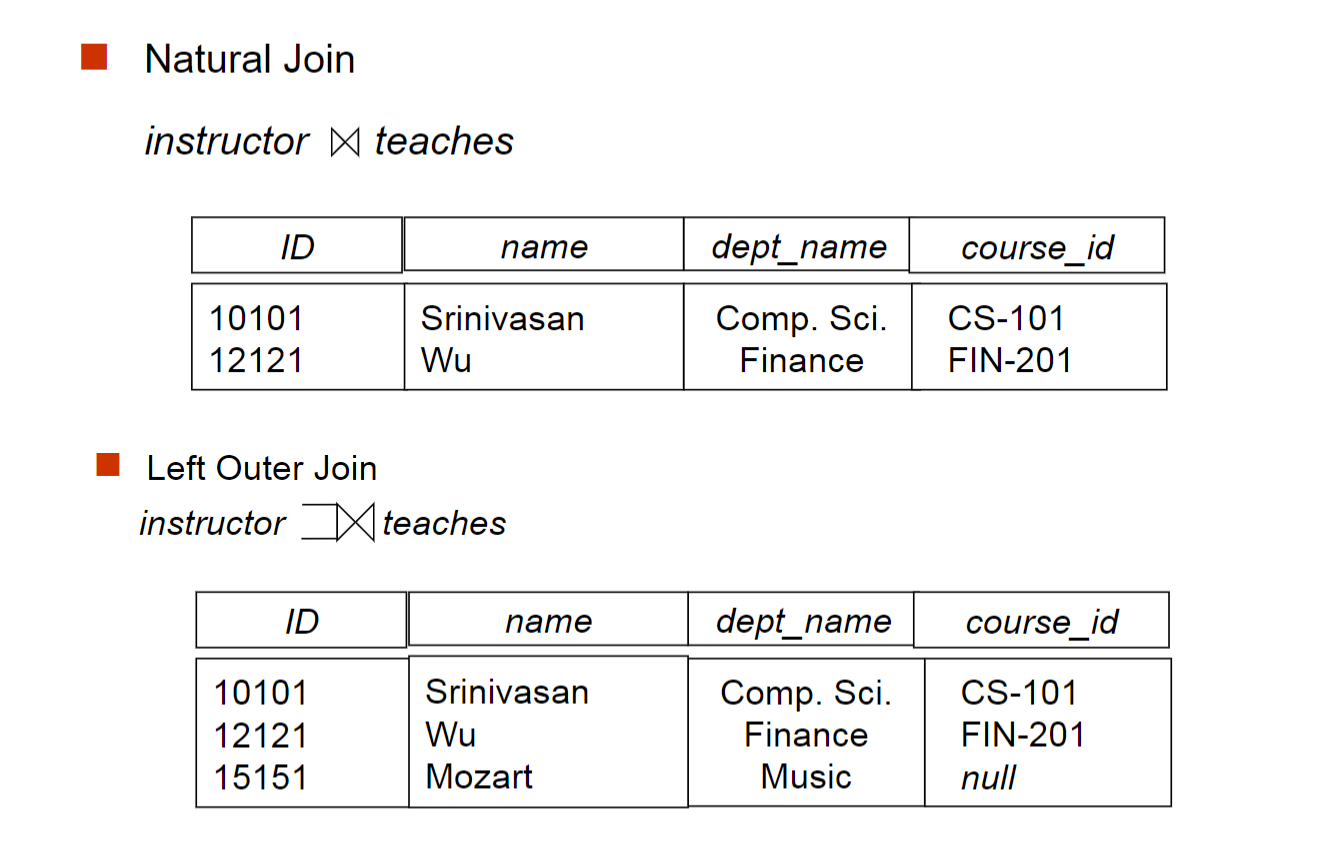
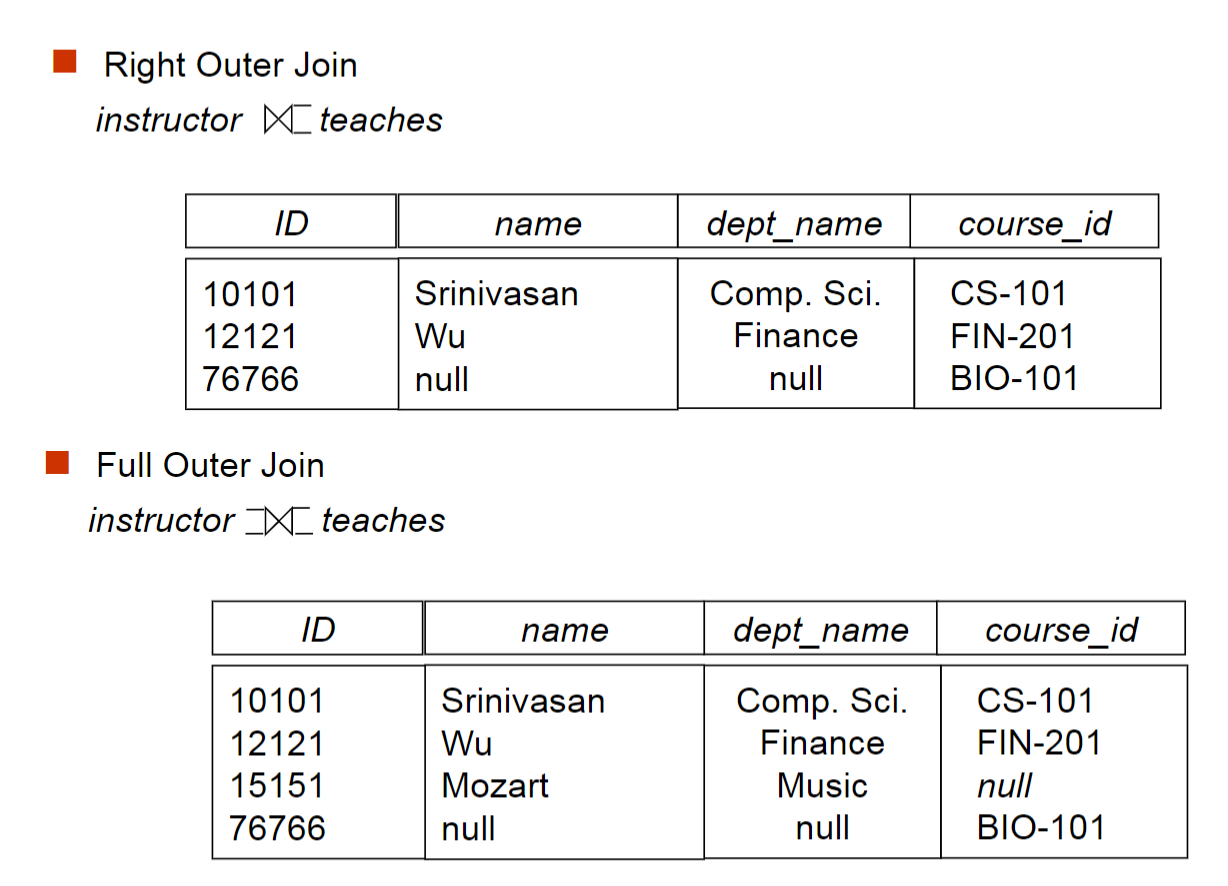
利用join来简化笛卡尔积
利用outer join
- 利用outer join, 找出所有没有学生的顾问的姓名: (left outer join)
注意判断为空用is null
- 找出有超过 5 个来自 "CS" 学院的学生的顾问的姓名:
SELECT i.name
FROM instructor i
JOIN advisor a ON i.ID = a.i_ID
JOIN student s ON a.s_ID = s.ID
WHERE s.dept_name = 'CS'
GROUP BY i.ID
HAVING COUNT(*) > 5;
查询的总结
- group by 写在where后面
- 排序: order by author_id asc
- case: when... then end https://leetcode.com/problems/capital-gainloss/
找最大的
select=max select top
找选所有课的: 可用not exist
https://leetcode.com/problems/customers-who-bought-all-products/
select customer_id
from Customer
group by customer_id
having count(distinct product_key)=(
select count(*) from Product
)
Modification
删除
插入
更新
update tablename set xxx=yyy where ...
update instructor
set salary = case
when salary <= 100000 then salary*1.05
when 100000 < salary <=200000 then salary*1.04
else salary *1.03
end

Integrity Constraints
foreign key
foreign key可以指向相同表,如用来刻画等级关系()
create table employee(
id varchar(255),
manager varchar(255),
primary key(id),
foreign key (manager) references employee
)
级联删除: 如果table2中key1=x元素被删除,table1中所有key1=x的也被删除