4 Processor
复习题: 4.6
Pipeline
流水线: 4-6
异常: 马德智云 4-25的一部分
多发射: 马德智云2
4个中间阶段寄存器组 IF/ID ID/EX EX/MEM MEM/WB
- EX/MEM中的是ID/EX的上一条指令
- MEM/WB是
Data Hazard
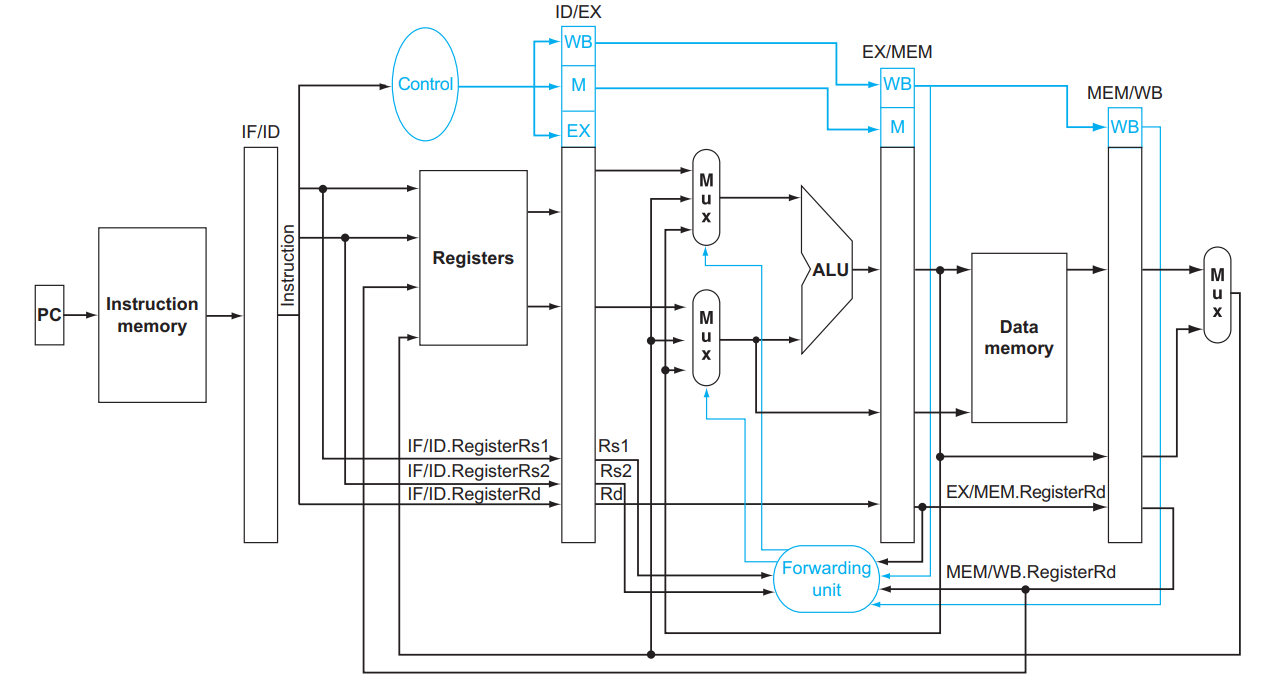
没有foward和hazard detection
如果没有fowarding解决harzard:
- 某条指令 (例如
#10)WB阶段做的寄存器更改,其之后第三条指令 (#13) 的ID阶段才能读出新的值; - 某条指令 (例如
#10)MEM阶段产生PCSrc = 1的信号,此时其之后第三条指令 (#13) 正在运行IF阶段,它运行结束后才会将PC置为实际上要跳转的指令
如果处理器无法解决harzard, 要想让程序正确执行,就需要在有关联的2条指令之间插入nop指令
见例题 和课后题4.18,4.20
Forwarding
修改Datapath,使ALU的输入可以来源于EX/MEM中(对应前1条指令ALU计算结果),或MEM/WB中的寄存器(对应前2条指令计算结果)
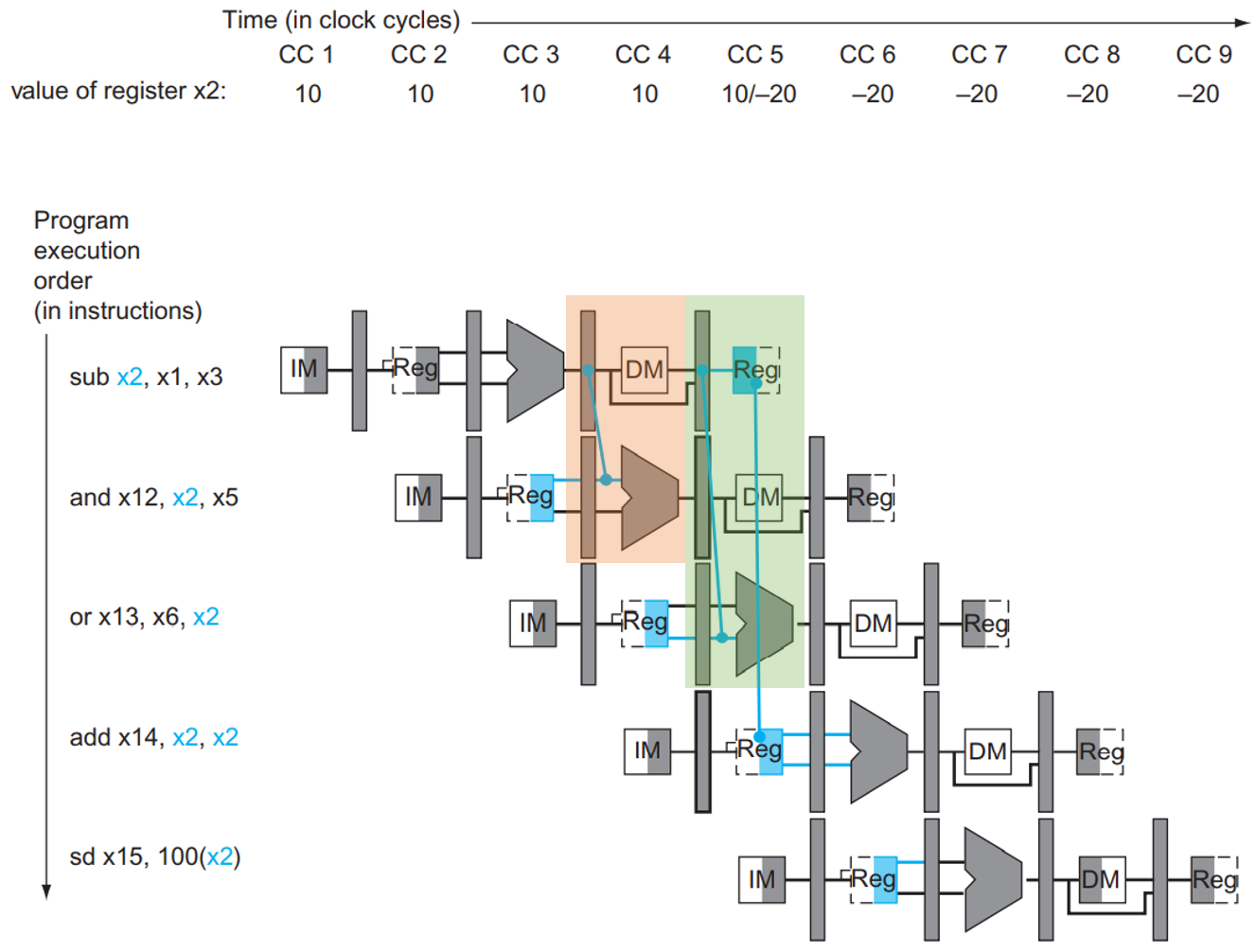
Harzard的条件


1a,1b是来自于上一条指令。2a,2b是来自于再上一条指令指令

Stalling
Forwarding可以,是因为EX和ID差了1轮
如果上一条指令是Load某个寄存器,当前指令要用该寄存器,但MEM和Reg差了2轮,所以获取不到。只能等下一轮.
条件: if (EX.MemRead && EX.Rd == ID.RsX) RsX代表Rs1或Rs2
如何Stall?
- ID/EX.WB,M,EX控制信号设为0
- 不更新PC和IF/ID寄存器
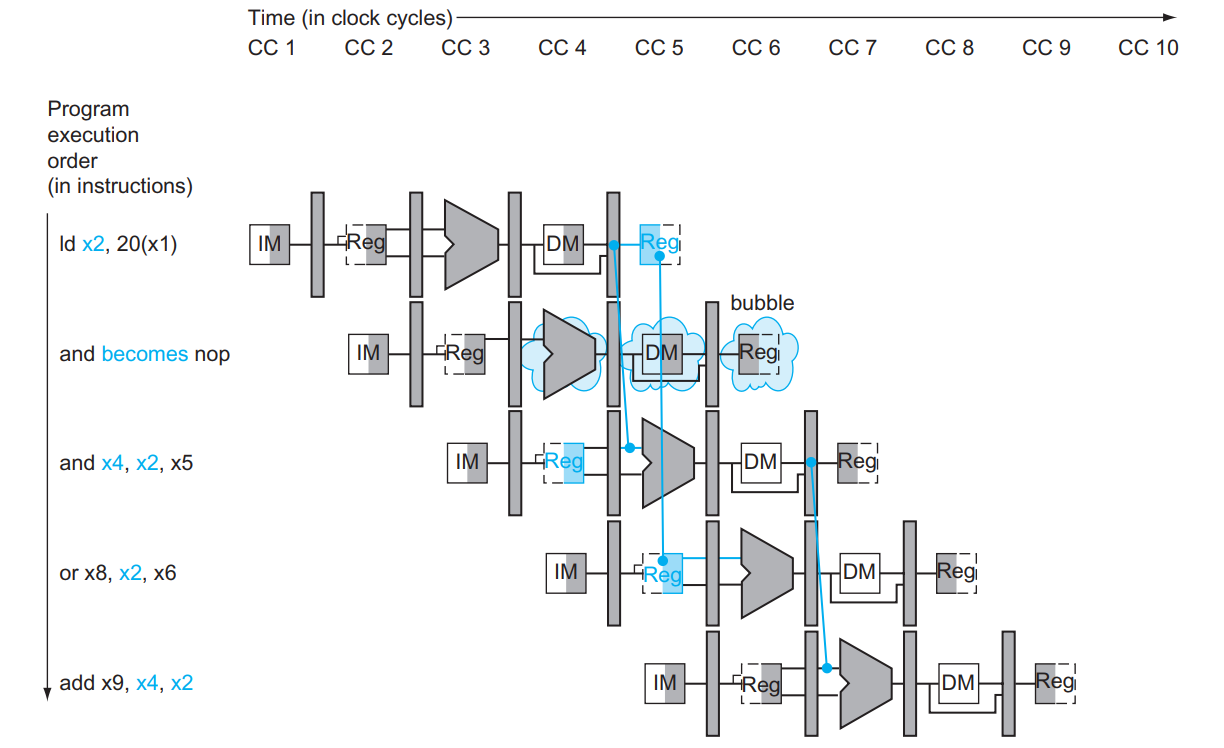
寄存器堆的double bump机制

Control Harzard
Stall on branch
原因:beq x1,x0,LABEL等要EX完才知道PC要跳转到哪里。EX和IF差了2轮。所以要stall, 等上一条beq执行完,再根据PC取指令
Reduce Branch delay
在ID阶段,增加Target address adder(提前计算PC+offset). Register comparator (提前对rs1,rs2进行比较)
dynamic branch prediction
branch prediction buffer 记录跳转目标地址. 有一个bit来指示预测的分支地址是被“采纳”(take)还是被忽略(not take)。这个位就是所谓的“take bit”。
1-bit: 如果每错一次就改变,那么可能会连续错2次。如二重循环。
2-bit mispredictor: 连续错2次,才改变预测
Exception and Interrupt
- exception: CPU内部
- interrupt: CPU外部 如I/O
RISC-V Privilege Mode
- U(user) < S(supervisor) < M(Machine) 优先级从低到高
- 每个模式有自己的ISA extensions
Instructions
Interrupt Registers
- mstatus
- mtvec: 中断触发后跳转到的地址 Mode=0 固定地址

- mepc: 存储中断发生时的PC值

- mcause: 中断原因 可跟mtvec一起,跳转

Multiple Issue
流水线只是减少了时钟周期的长度,但是平均下来每个周期\(CPI=1\)
多发射
Static Dual Issue
ALU没用到MEM, Store没用到WB. 流水线利用不够充分
- 添加一个加法器来计算Load/Store指令的地址
一个时钟周期同时执行一条ALU 和L/S指令

但是可能有依赖关系,不一定能同时执行
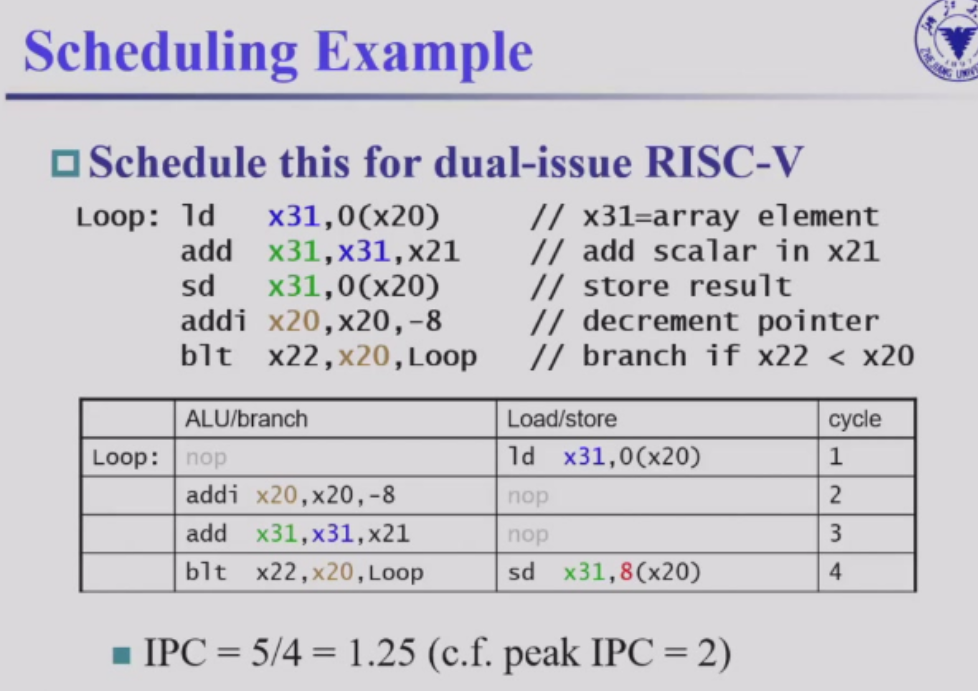
Loop Unrolling

循环展开,每个循环不是处理数组1个数,而是每个循环处理4个数,存到x28-x31 3个寄存器。4条ld,add,sd指令. 用C语言来类比:
for(int i=n-1;i>=0;i--) s[i]+=x;
//展开后:
for(int i=n-4;i>=0;i-=4){
s[i]+=x;s[i+1]+=x;s[i+2]+=x;s[i+3]+=x;
}
register renaming
Dynamic


- Pipeline : the basic idea is easy, the devil is in the details(data hazards...etc)