Ch2. cache and memory
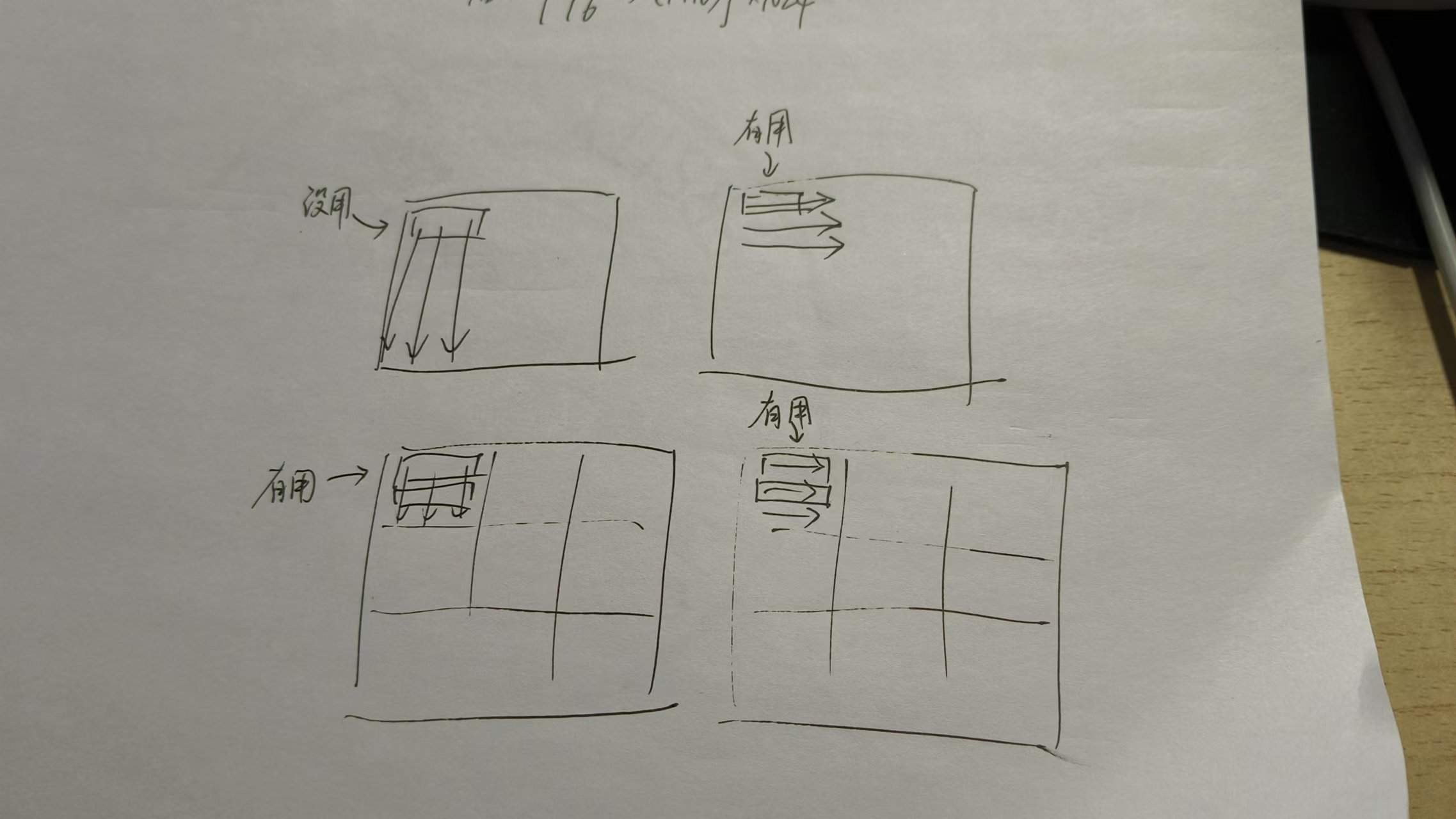
Block Placement
Block Identification
Block replacement
FIFO
注意是插入时间,不是被使用的时间。 *代表最早进来的的元素
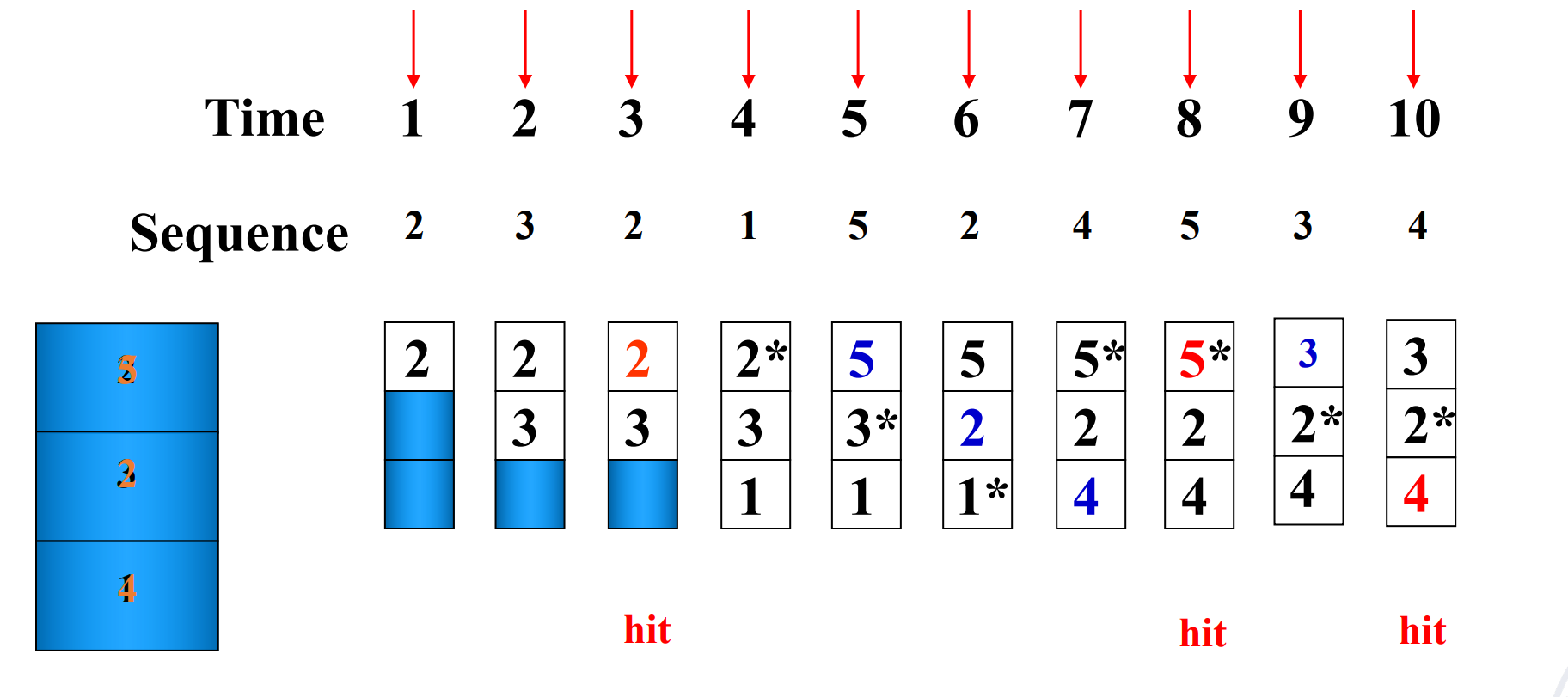
LRU
Least-recently used (LRU) - pick the block in the set which was least recently accessed 但是假设大小为3, 按1 2 3 4 1 2 3 4这样访问就会全都miss.
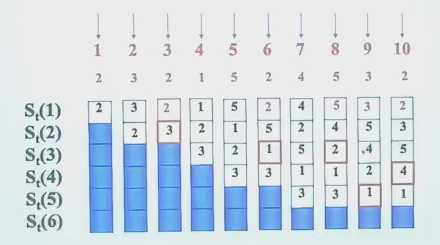
用栈来模拟 LRU: 栈顶是最近访问的,栈底是最久未访问的,每次要替换的时候,替换栈底的元素,然后把新元素插到栈顶。如果hit,就把命中的元素提到栈顶。通过下面的图可以快速看到栈大小为 n 时的命中率。
LRU的硬件实现:
有n个块,用\(C(n,2)\) 个触发器
\
先定义三个比较器代表AB,AC,BC的大小顺序。如果替换的是C,就有ABC,BAC两种。代入写出表达式

stack replacement
命中率随着缓存大小n 增大非下降的算法称为 stack replacement 算法。
- LRU是,FIFO不是 \(B_t(n)\) 表示时间t,大小为n的缓存里的序列 \(B_t(n)\in B_t(n+1)\), 则命中率
Write Strategy
-
Write Hit
- Write Through:直接写到Cache和内存。(内存和Cache内容同步,不需要dirty bit) 写到内存的时间较长,这个过程需要 Write Stall,或者使用 Write Buffer。
- Write Back:只在 Cache 中写,同时通过一个额外的 dirty bit 表示这个块已经被修改。只有要替换的时候,才把dirty的块写入内存
-
Write Miss
- Write Around(no write allocate):直接写到内存。
- Write Allocate:将要写的块从内存读到 Cache 中(如果是dirty需要先写回内存),再写Cache。
Write through和Write around配对 Write back和Write allocate
Cache性能分析
参考下计组笔记和A4
- Cache miss的分类
- block size,cache size等对性能的影响
计算题
 \(CPI=1.1+ 0.3*0.1*50 + 1*0.01*50=3.1\)
\(AMAT=(1/1.3)(1+0.01*50)+(0.3/1.3)(1+0.1*50)=2.54\)
注意AMAT里面 取指令和取数据的比例是1:0.3 然后加权平均一下
\(CPI=1.1+ 0.3*0.1*50 + 1*0.01*50=3.1\)
\(AMAT=(1/1.3)(1+0.01*50)+(0.3/1.3)(1+0.1*50)=2.54\)
注意AMAT里面 取指令和取数据的比例是1:0.3 然后加权平均一下
 记得算指令
记得算指令
多级缓存
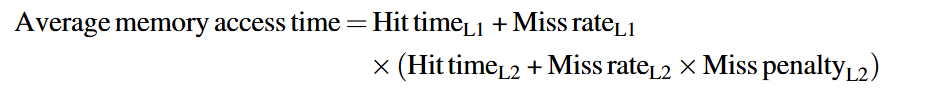 这里有两种miss rate
这里有两种miss rate
- 公式里的L2 miss rate是local miss rate(分母是访问L2的次数)
- 但是也有global miss rate(分母是所有内存访问的次数)
- 比如1000次内存访问, 40次L1miss 20次L2 miss. 那公式里的local miss rate L2 就是 20/40=0.5 global miss rate是20/1000=0.02
具体的代码


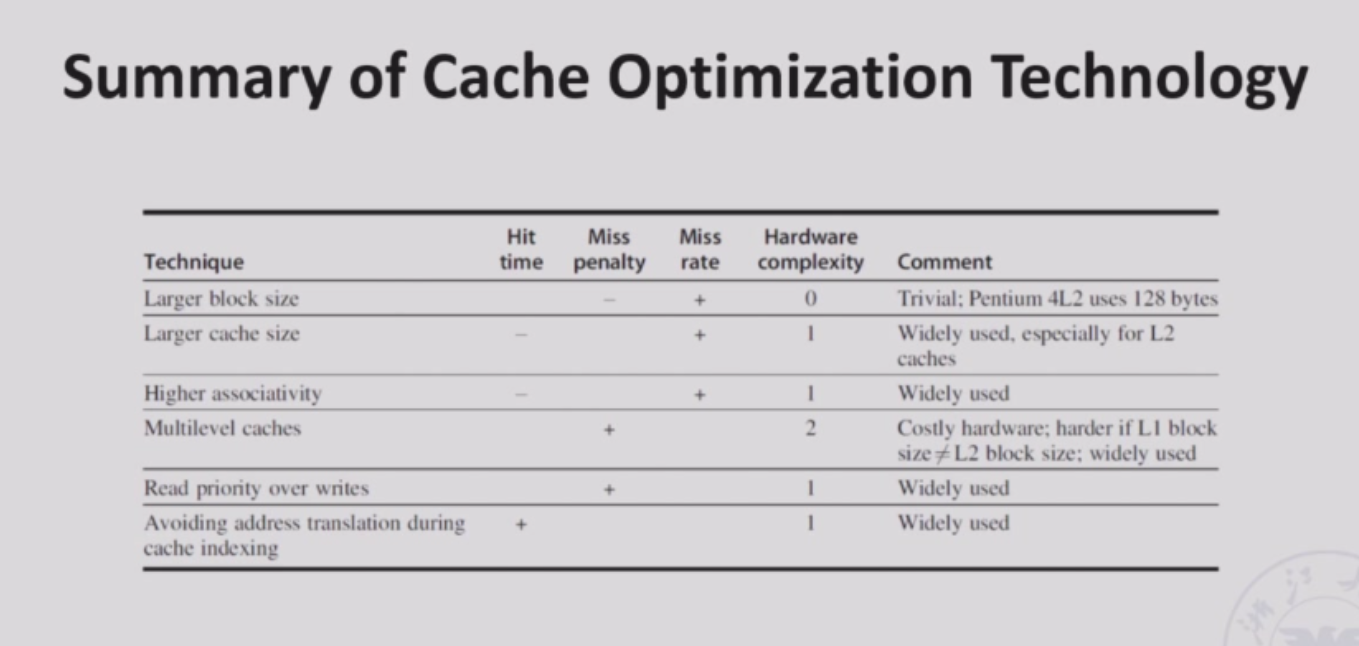
Basic optimization
这一部分在课本的附录B,容易被忽略

Cache miss的分类

Larger block size:
- 好处: 减小compulsory miss (空间局部性)
- 坏处: 增加conflict miss(总大小不变, 块变少了), 增加miss penalty
- 所以随着块大小增大不一定好
Larger Cache:
- 好处: 减小capacity miss
- 坏处: 功耗大, hit time增加
Higher associativity:
- 好处: 减小miss rate
- a direct-mapped cache of size N has about the same miss rate as a two-way set associativecache of size N/2. This held in three C’s figures(指三种miss) for cache sizes less than 128 KiB
高级优化
Reduce hit time (4)
-
Small and simple first-level caches:
一级缓存(L1 Cache)设计为小而简单,以减少访问延迟。通过简化结构(如减少复杂逻辑)来提高访问速度。 -
Way prediction:
预测缓存行的组选择(Way),以减少访问缓存时的分支预测开销。通过提前预测缓存行的位置,减少命中时间。 -
Avoiding address translation:
避免虚拟地址到物理地址的转换,直接使用物理地址访问缓存。减少地址转换的开销,从而加快访问速度。 -
Trace cache:
一种特殊的缓存,存储指令的执行路径(Trace),而不是简单的指令块。通过存储最常用的指令序列,减少指令缓存的命中时间。
Increase bandwidth (3)
-
Pipelined caches:
将缓存访问过程流水线化,允许多个访问请求同时进行。通过并行处理多个请求,提高数据传输速率。 -
Multibanked caches:
将缓存分成多个独立的存储单元(Bank),允许多个访问请求并行处理。通过增加并行度,提高带宽。 -
Non-blocking caches:
允许在缓存未命中时继续处理其他请求,而不是阻塞等待。通过减少阻塞时间,提高带宽利用率。
Reduce miss penalty (5)
-
Multilevel caches:
使用多级缓存(如L1、L2、L3),在未命中时从更高级缓存中获取数据。通过减少访问主存的频率,降低未命中惩罚。 -
Read miss prior to writes:
在写操作之前,先检查是否有未完成的读操作,避免写操作阻塞。通过优化写操作的顺序,减少未命中惩罚。 -
Critical word first:
在未命中时,优先获取处理器急需的数据(关键字),而不是等待整个块的数据。通过快速提供关键数据,减少未命中惩罚。 -
Merging write buffers:
将多个写操作合并为一个,减少写操作的延迟。通过减少写操作的开销,降低未命中惩罚。 -
Victim caches:
在缓存未命中时,检查一个小的缓存(Victim Cache),存储最近被替换的数据。通过快速检查Victim Cache,减少未命中惩罚。
Reduce miss rate (4)
-
Larger block size:
增加缓存块的大小,以捕获更多的相关数据。通过增加空间局部性,减少未命中概率。 -
Large cache size:
增加缓存的容量,以存储更多的数据。通过增加缓存的覆盖范围,减少未命中概率。 -
Higher associativity:
增加缓存的关联度(如从直接映射到组相联),减少冲突未命中的概率。通过提高灵活性,减少未命中概率。 -
Compiler optimizations:
通过编译器优化(如循环展开、数据对齐),提高程序的局部性。通过优化代码结构,减少未命中概率。
Reduce miss penalty or miss rate via parallelization (1)
- Hardware or compiler prefetching:
硬件或编译器预测未来的数据访问,提前将数据加载到缓存中。通过提前获取数据,减少未命中惩罚或未命中概率。
虚拟内存
类比Cache的4个问题
- block placement: fully associative。因为miss penalty太大了。
- block identification: Page table
- replacement:LRU...
- write: 用write-back, 有dirty bit. 如果每次写磁盘,代价太高不能接受。
分页/分段
见OS笔记
页是一维的(只需要页号)。 内部碎片。
段是二维的(每段长度不一样,需要知道段的起始地址和长度)。外部碎片(内存中)

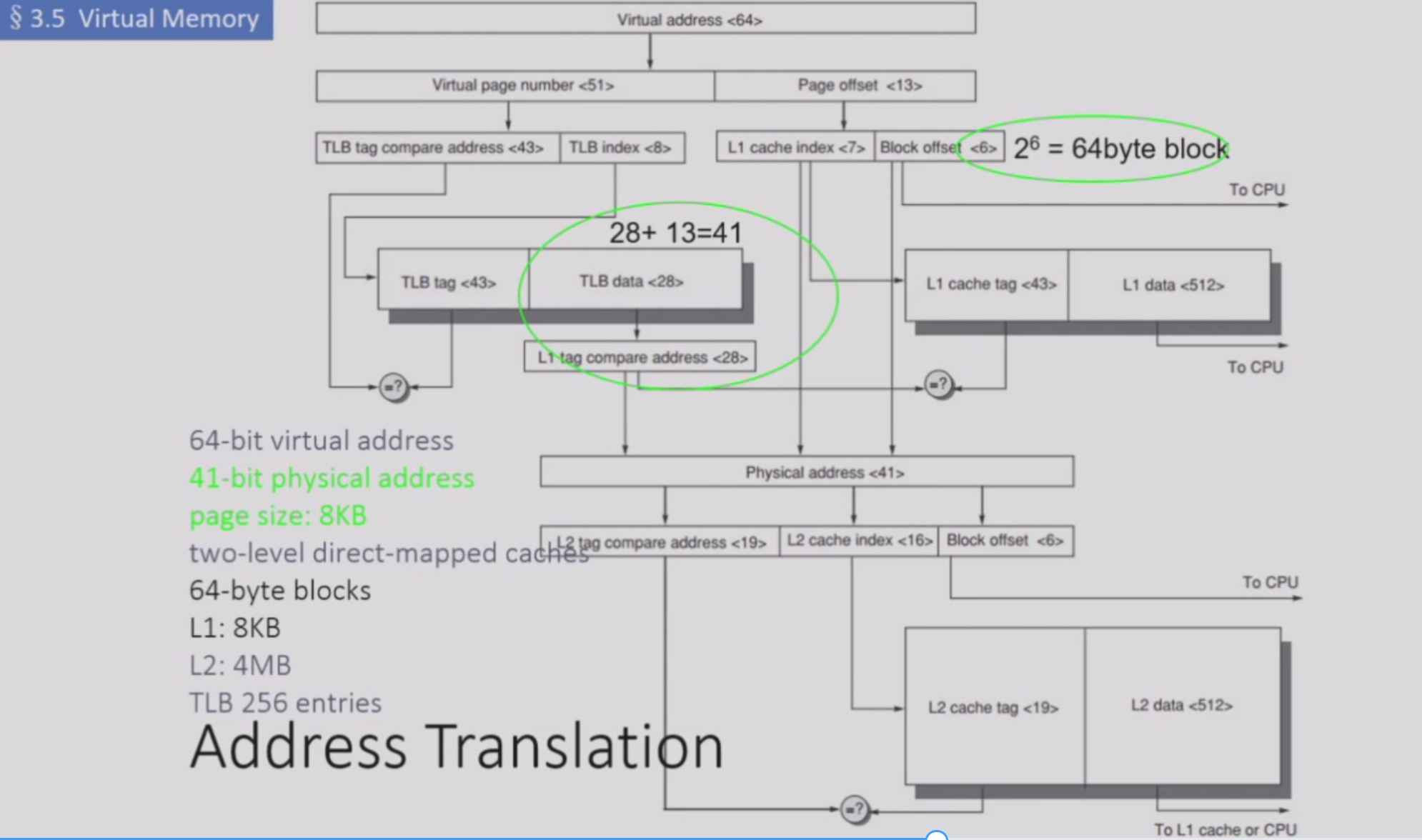
地址转换
注意这里既有单位是Page的TLB,也有单位是block的Cache 常瑞ppt 49/82
page size 8KB page offset 13bit
- TLB: 根据256entry, index 8位, 那么TLB tag=虚拟地址64-8-13=43. TLB data=物理地址41-13=21
- L1 cache: 64B的block, block offset=6 大小8KB对应\(2^7\)个block, index=7 L1 tag=TLB tag=43 L1 data=64*8=512
- L2 cache offset=6 大小4MB 对应index=16
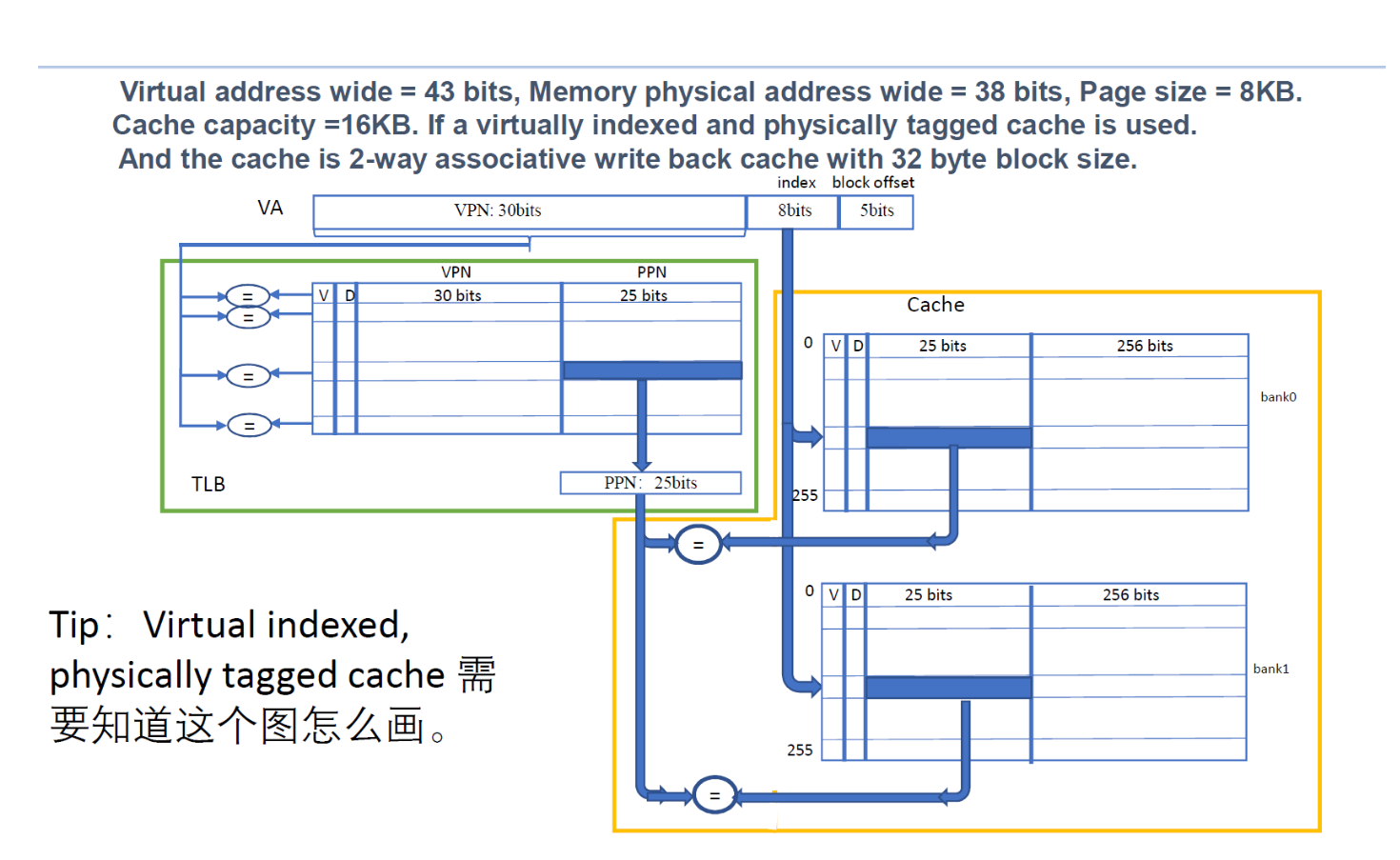
Virtual indexed physically tagged
8KB offset=13 VPN=30 PPN=25
Cache的tag用的是物理地址 tag=PPN=25 1个block 32B,2-way就是64B, 16KB就是256个block index=8 offset=5