2.Parsing
递归下降
top-down parsing: 从S开始尝试各种推导,直到推出输入的字符串
LL(1)
Nullable,First,Follow Sets
Nullable(X) = True if X ->* ε ->*代表任意多步推导
FIRST(γ): if γ ->* tβ, then t ∈ First(γ) 代表γ经过推导后开头可能出现的终结符
遍历X在左边的所有

FOLLOW(X): if S ->* βXtδ, then t ∈ Follow(X) t代表字符串X 紧跟着出现的终结符

- 第一条比较好理解
- 第二条是因为 Y->Xβ 当β是空的时候, Y后面跟的字符 也是 X后面可能跟的字符
LL(1) parsing table
parsing table:行是非终结符\(X\), 列是终结符\(t\)
对于每条规则\(X\to \gamma\)
- \(\forall t \in \text{First}(\gamma)\) 把规则填入X行t列
- 如果\(\gamma\) 是Nullable, \(\forall t \in \text{Follow}(X)\) 把规则填入X行t列
LL(1) grammar: 获得的parsing table的每一栏只没有重复的规则
- Left-to-right parse, Left-most derivation, 1 symbol lookahead
对于LL(k) 则每列不是1个终结符, 而是k个终结符
Eliminate Left Recursion
left recursion的定义: 左边 = 右边第一个非终结符 比如\(A\to Aa, A\to b\)
- \(\text{First}(a)\subseteq \text{First}(Aa)\) 则parsing table里面必然有重复
通过重写规则消除左递归: \(A\to bA',A'\to aA', A'\to\)
Error Recovery
LR(0)
bottom-up parsing: 把输入字符串逐渐变回起始符号S
LR(0) parsing
一些符号:
- .代表parser的位置
- 为了处理EOF 加入一条规则S'->.S$ $代表EOF S'是新的起始符号 S是原来的
The parser performs several actions:
- shift: push next input onto top of stack
- reduce R: top of stack should match RHS of rule R (e.g., X -> A B C) pop the RHS from the top of stack (e.g., pop C B A) push the LHS onto the stack (e.g., push X)
- error
- accept: shift $ and can reduce what remains on stack
Closure

- closure: 如果.后面立刻跟着非终结符X,就把他取出来
- goto: 把.向右移动一个格子 不管X是终结符还是非终结符
- reduce: .在最后了 就根据对应的规则编号
- accept: S'->S.$

LR(0) parsing table
构建parsing table

使用: 根据当前状态进行转移,并进行shift/goto/reduce/accept
- 如果是reduce操作,只跟状态有关,而跟当前input token无关。
- 如果是shift, 可以理解为先shift再判断,不需要look-ahead(根据next-input token) 所以这个语法被称为LR(0)
SLR
在LR(0),对于任意终结符\(c\) \(T(i,c)\) 都是reduce k, 但是产生式k后面不一定就紧跟着c. 可以用产生式k左边符号的follow集合
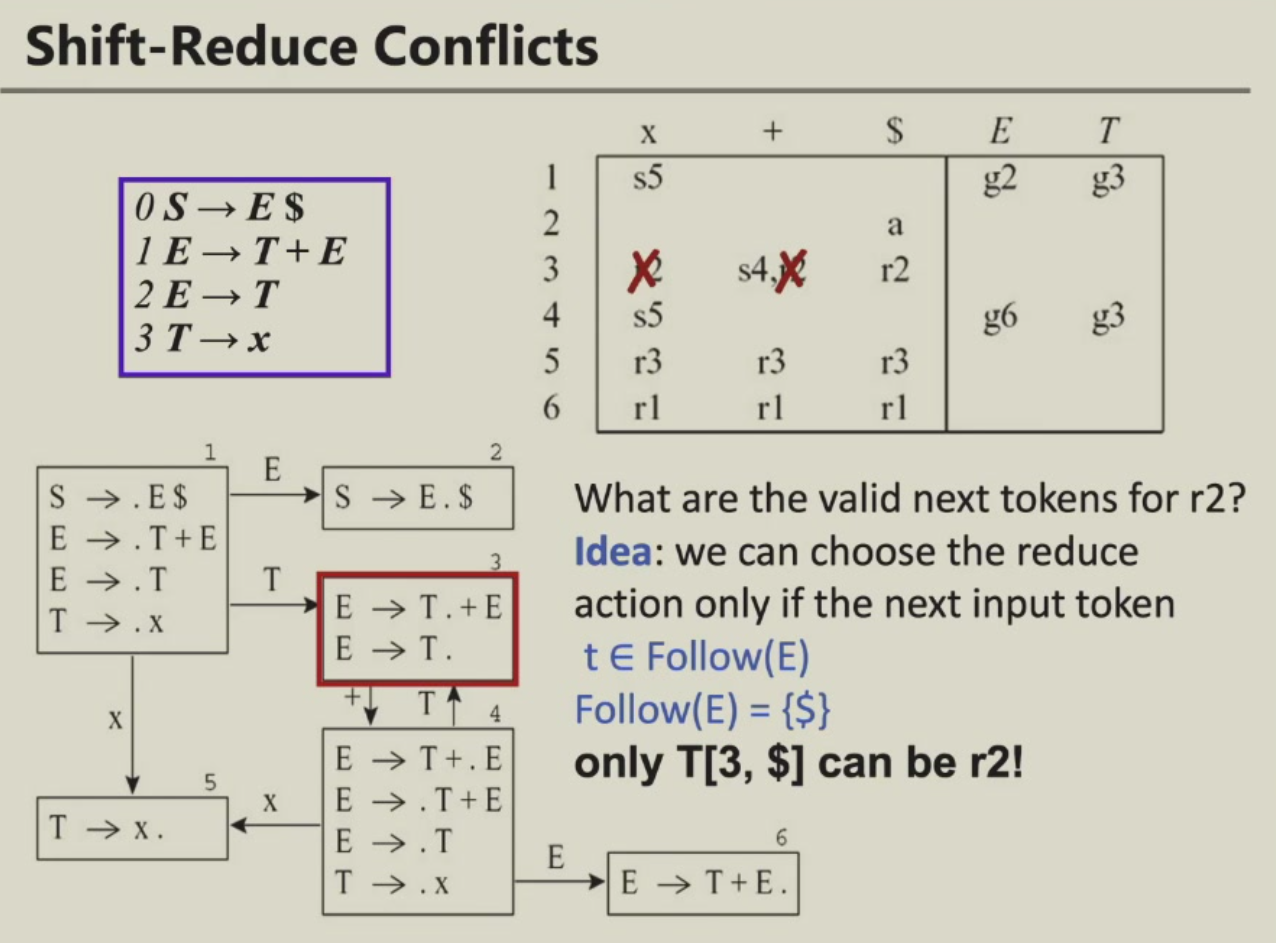

LR(1)
扩展状态, 每个状态是(A->B,z) 前面是规则 后面是lookahead 字符,代表要往后看1格是什么字符,然后决定转移。

- closure 1变成X的推导, 2变成 FIRST(βz)
- goto 1的.向右移动 2字符不变
- reduce 如果lookahead 是z,则利用这条规则reduce
LL(1)中first的算法


