1.Lexical Analysis
Regular Expression
定义
a: 字符aM|N: M或NMNM和N连接M*>=0个MM+>=1个MM?0个或1个M[a-zA-Z].除了换行符之外的任意字符"a.+*"引号表示字面字符串
消除歧义歧义:
- longest match: 选择能够匹配某一个表达式的最长字串
- rule priority: 从上到下
DFA
priority的实现: 根据优先级,选择state的label
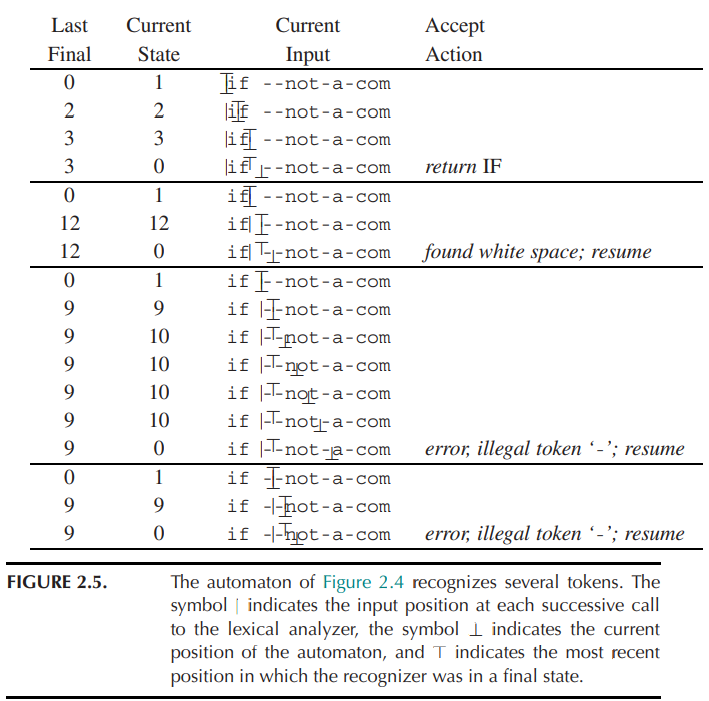
longest match的实现: 记录last final state, 以及处于final sate时的输入位置。 如果当前状态下,输入的字符无法转移。则return, 并更新input position (|:input position ⊥: automaton position T: last final)
- 
NFA
正则表达式转NFA
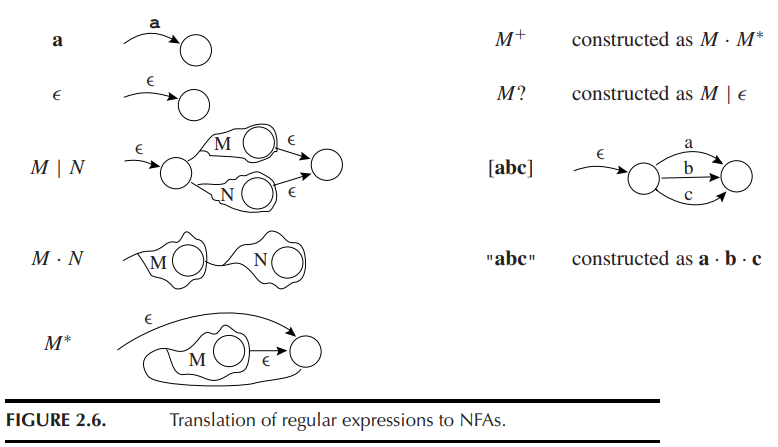
NFA转DFA
[!important] 定义\(E(q)\) 为M中所有可以从q通过空串转移到的状态。\(\{p\in K|(q,e) (p,e)\}\)
- \(K'=2^K\) 2. \(\Sigma=\Sigma'\) 3. \(s'=E(s)\) 4. \(F'=\{Q|Q \subseteq K,Q\cap F \neq \emptyset\}\)
- 对于任意集合\(Q\subseteq K\), \(a\in\ \Sigma\) 对Q中元素q,找到(q,a)在NFA的转移p
\[\begin{aligned} \delta'(Q,a)=\bigcup \{E(p)|q \in Q,(q,a,p)\in \delta\} \end{aligned}\]
NFA最小化
【编译原理速成(1) 词法分析&语法分析(上)】 【精准空降到 54:04】