Ch3.ILP
Dynamic Scheduling
把ID拆成2个阶段
- Issue(IS): 按顺序读指令, decode, 检测是否有结构冲突(使用相同部件,如加法器)。
- Read operand(RO): 等到没有数据冲突,就读操作数 (乱序执行
乱序执行会导致 WAR和WAW hazard (普通流水线中不会有问题,但是乱序之后会有。比如乱序先写后读)
总结
Toma:
- EX结束的时候的时间 = 操作数WB的时间+执行时间
- 不受部件限制,受保留站大小限制。(故t=2的时候第二条指令就IS了,不用等第一条执行完)
- Scoreboard在EX段乱序执行 而Tomasulo在RO段乱序
- 因为有寄存器重命名,所以WAR和WAW不需要等
ROB: 只需要加一列 顺序提交 commit(n)=max(WB(n)+1,commit(n-1)+1)
要看条件 填时间 / 可能会考某一个时刻的表状态。
Scoreboard
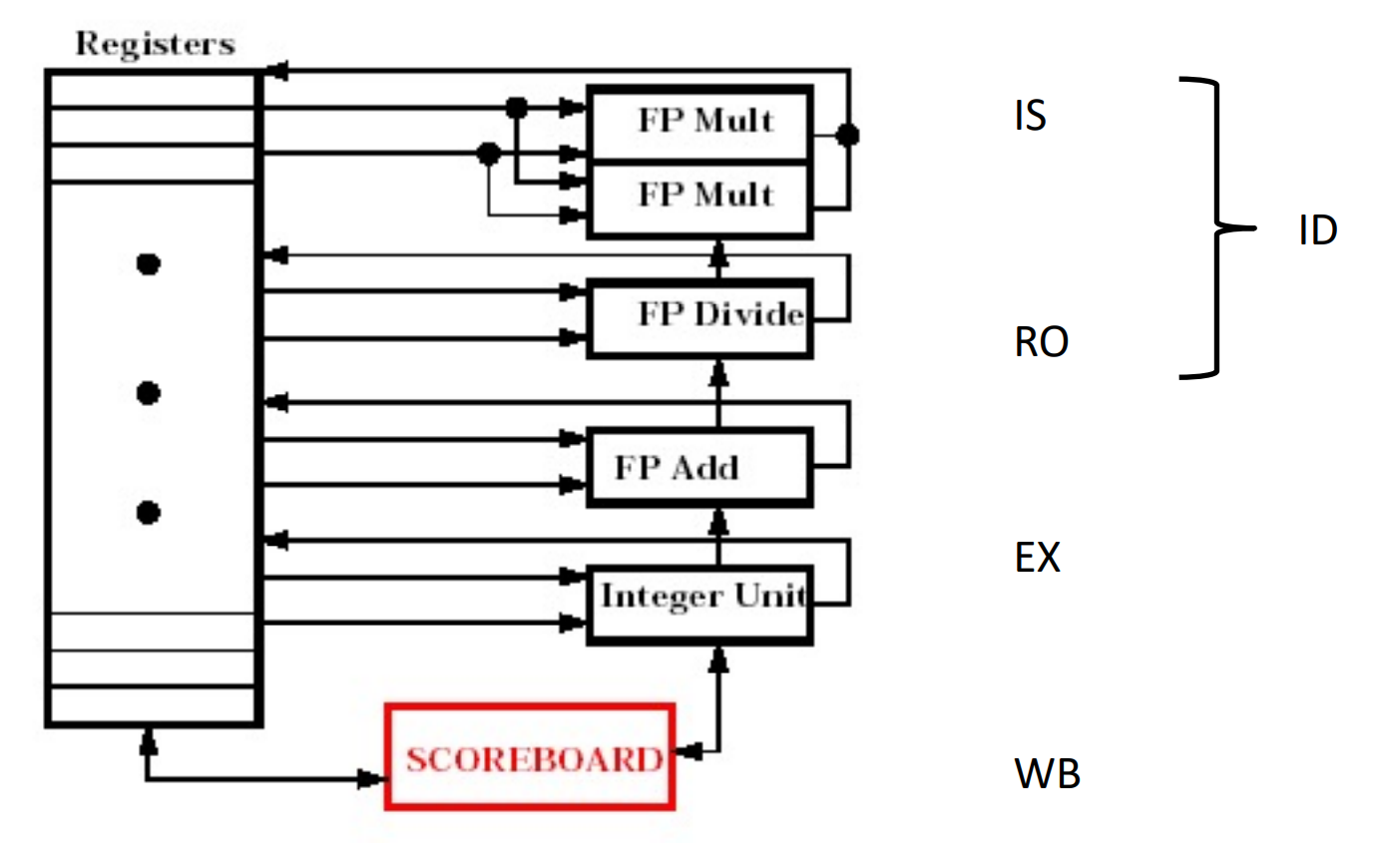
Integer是内存? 两个乘法器,因为乘法比较慢
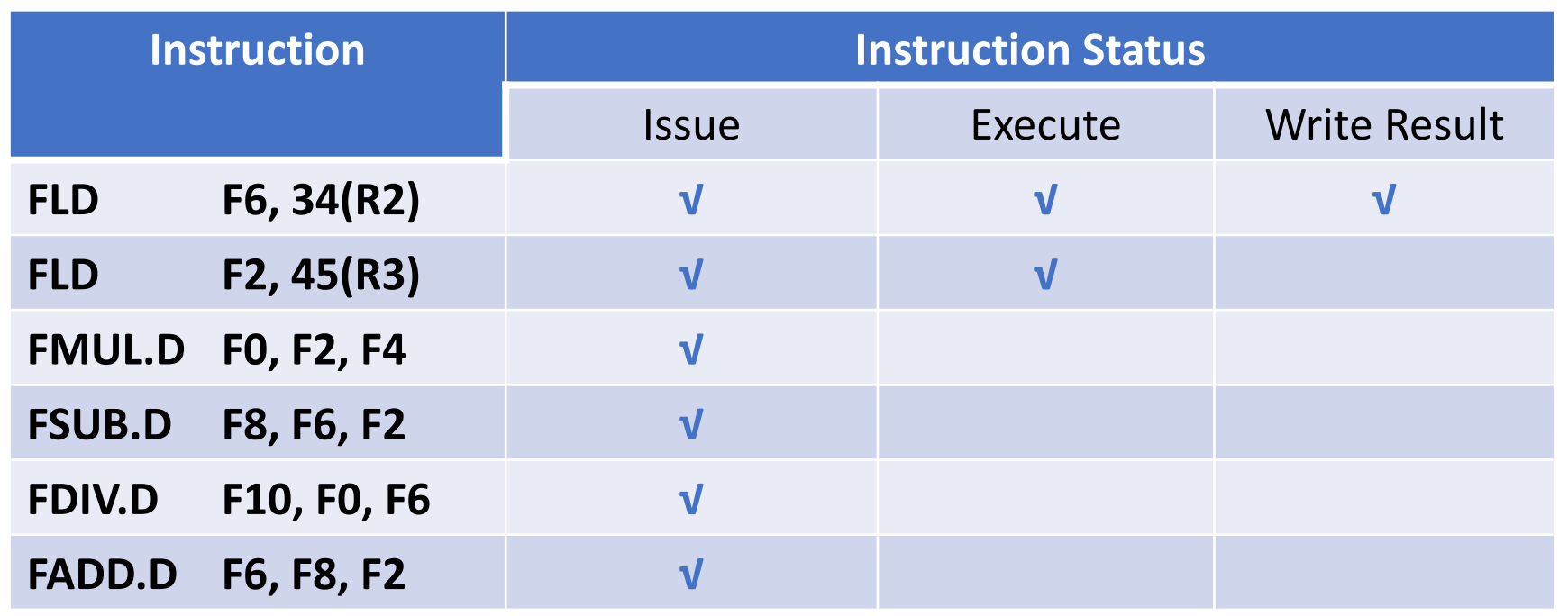
Inst Status
√表示完成这个阶段
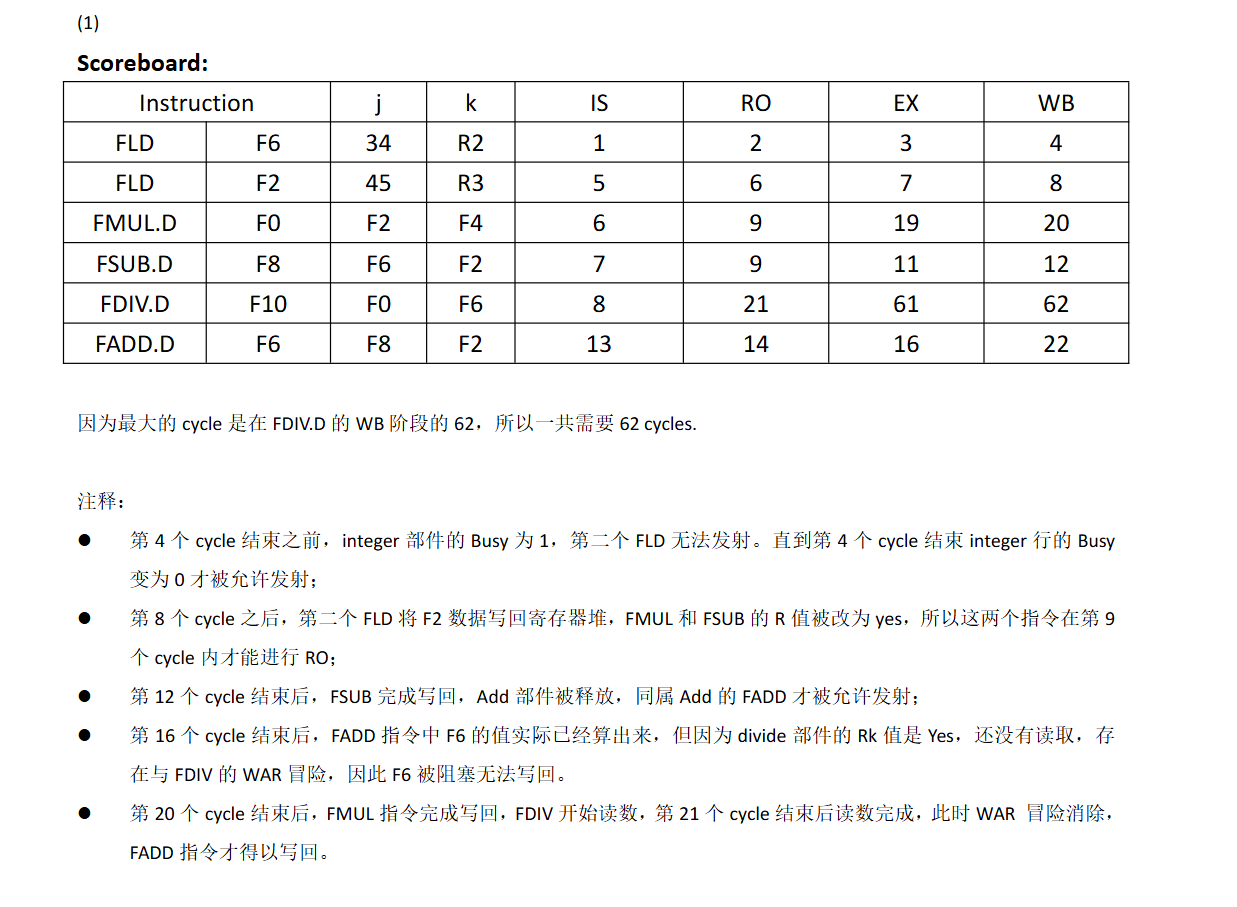
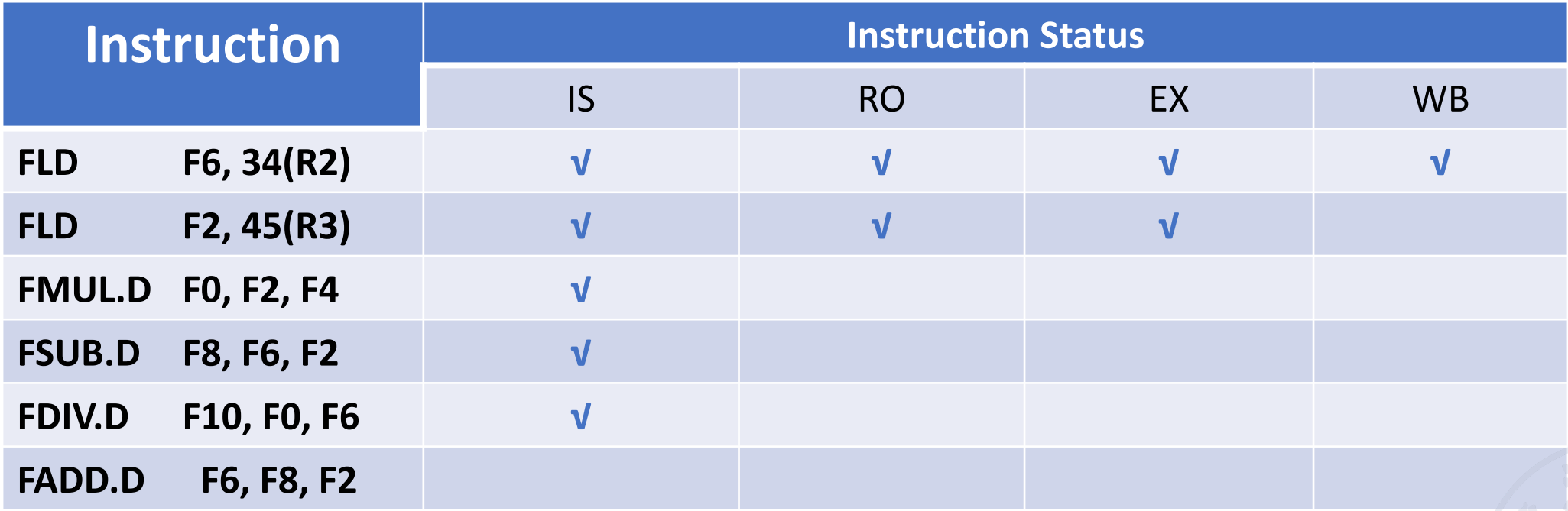 3,4在等待2的F2 5在等3,所以不能进入RO. 6的ADD和SUB都用到加法器,有结构冲突,所以不能进入IS
3,4在等待2的F2 5在等3,所以不能进入RO. 6的ADD和SUB都用到加法器,有结构冲突,所以不能进入IS
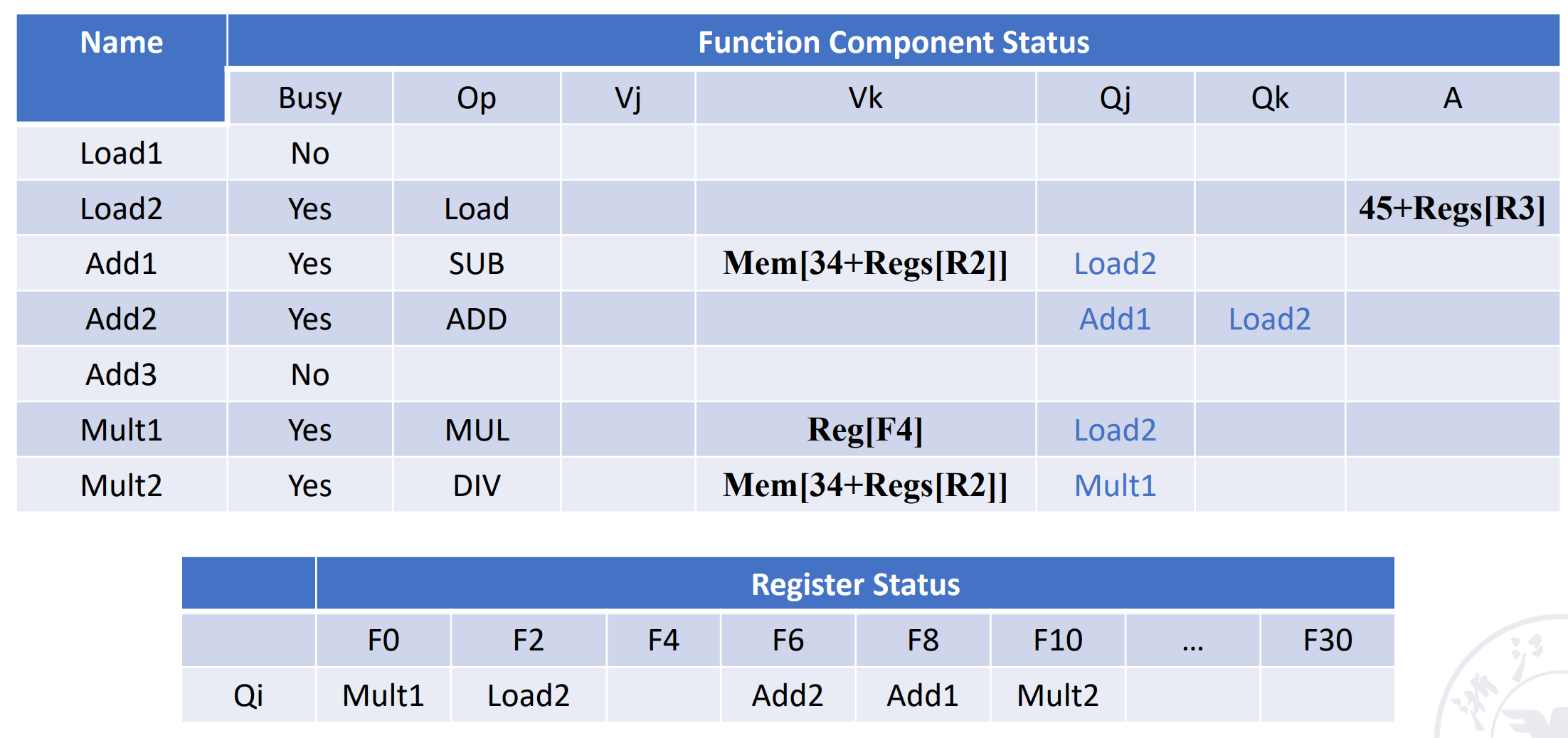
Func Comp Status& Reg Status
已经WB的不记录,只记录当前正在运行的。
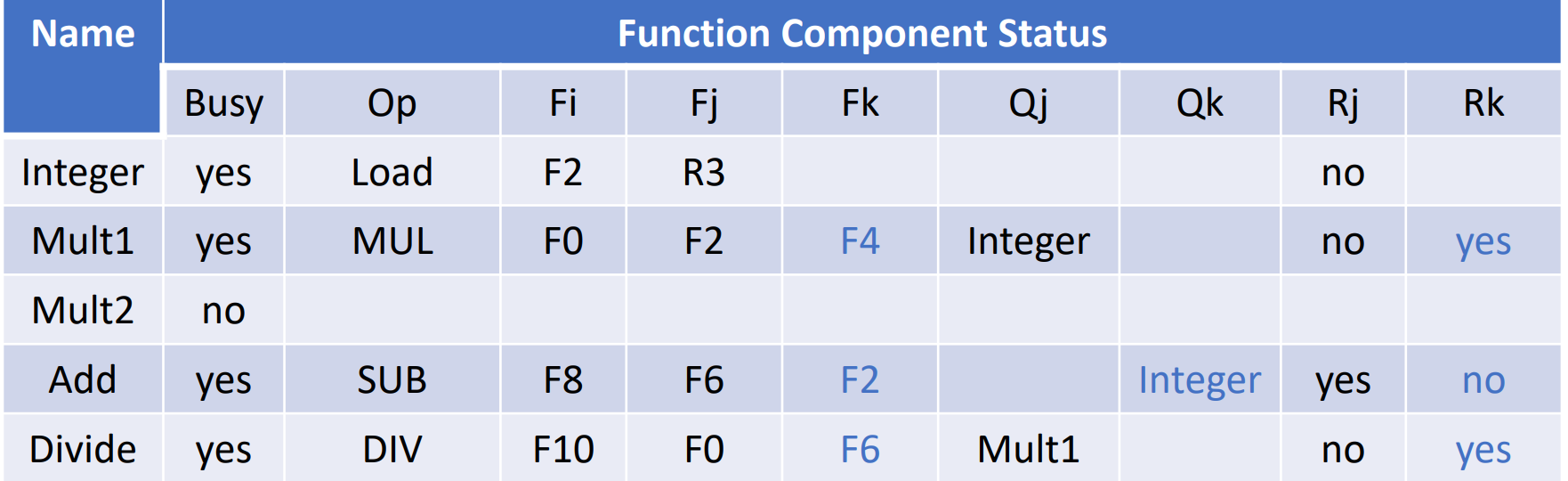
- busy 代表当前这个单元是否有指令正在使用。op 表示这个单元正在被哪类指令使用。
- Fi 为目的,Fj、Fk 为源操作数
- Qj, Qk 代表源操作数来自哪个部件如 Mult1 的 Qj=Integer 说明来自整数部件(此时正在执行 Load 指令)
- Rj、Rk 代表源操作数的状态
- yes: operands is ready but no ready. 没读是因为在等其他操作数。比如mul f0,f2,f4的f4
- no & Qj=null: operand is read. 指令已经过了RO阶段,在EX或WB。比如第二条指令的R3
- no & Qj!=null: operand is not ready. 其他指令会修改这个操作数,而且还没有执行完毕。
Register Status: 每个寄存器要被哪个部件写

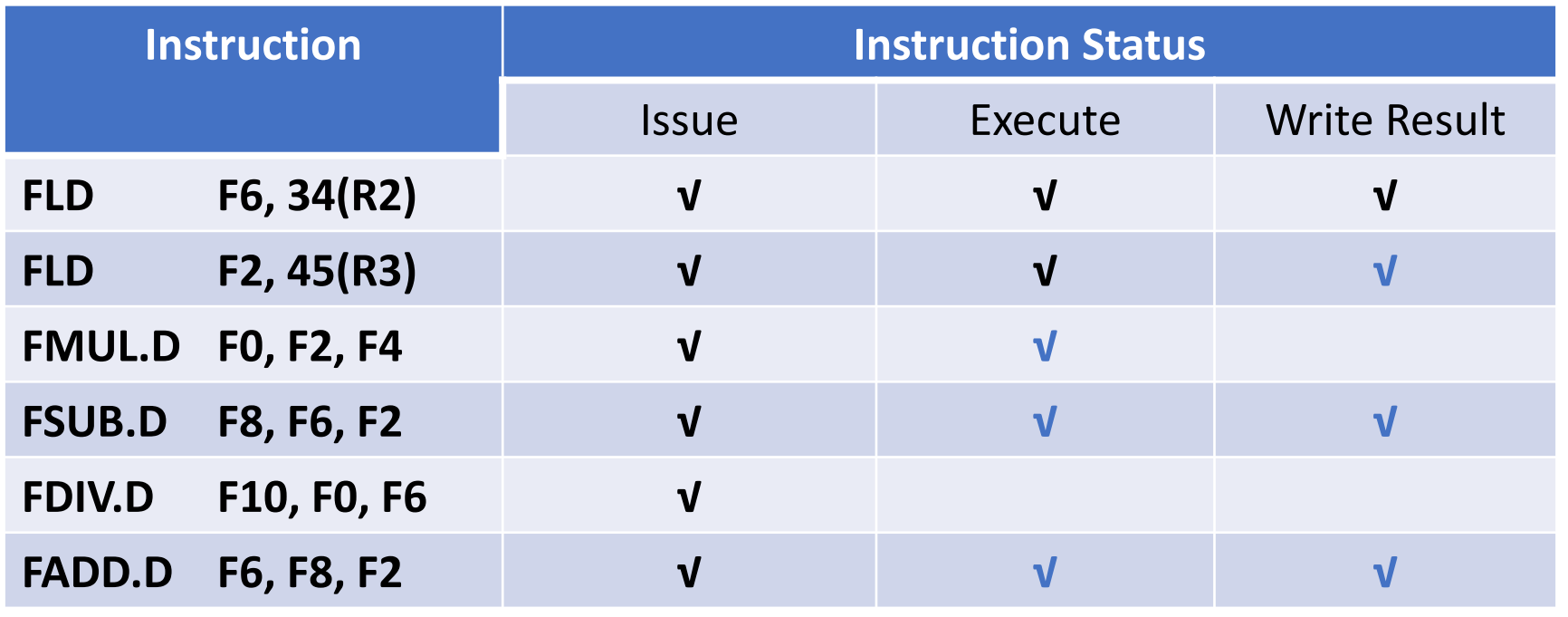
接下来 指令2WB了,指令3,4可以RO,EX。且加法比乘法快,所以指令4先WB, 这样指令6可以先执行,指令5还在等指令3
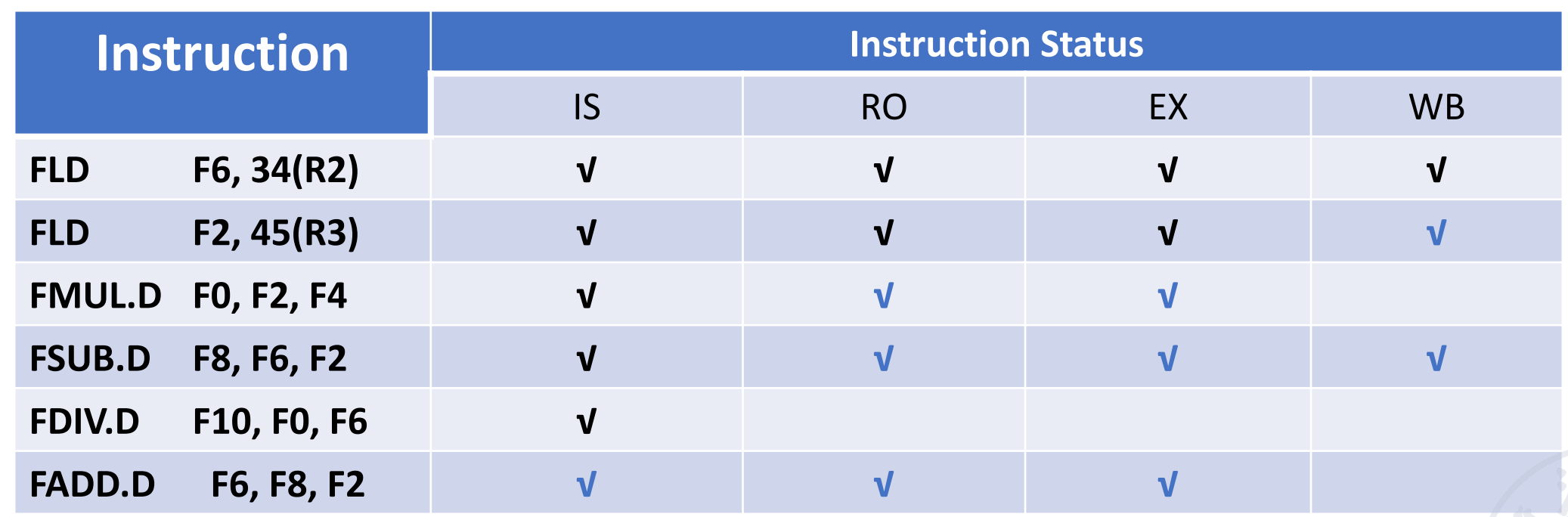 Mult和Add的指令已经在EX了,所以Rj=Rk=no,Qj=Qk=null
Mult和Add的指令已经在EX了,所以Rj=Rk=no,Qj=Qk=null
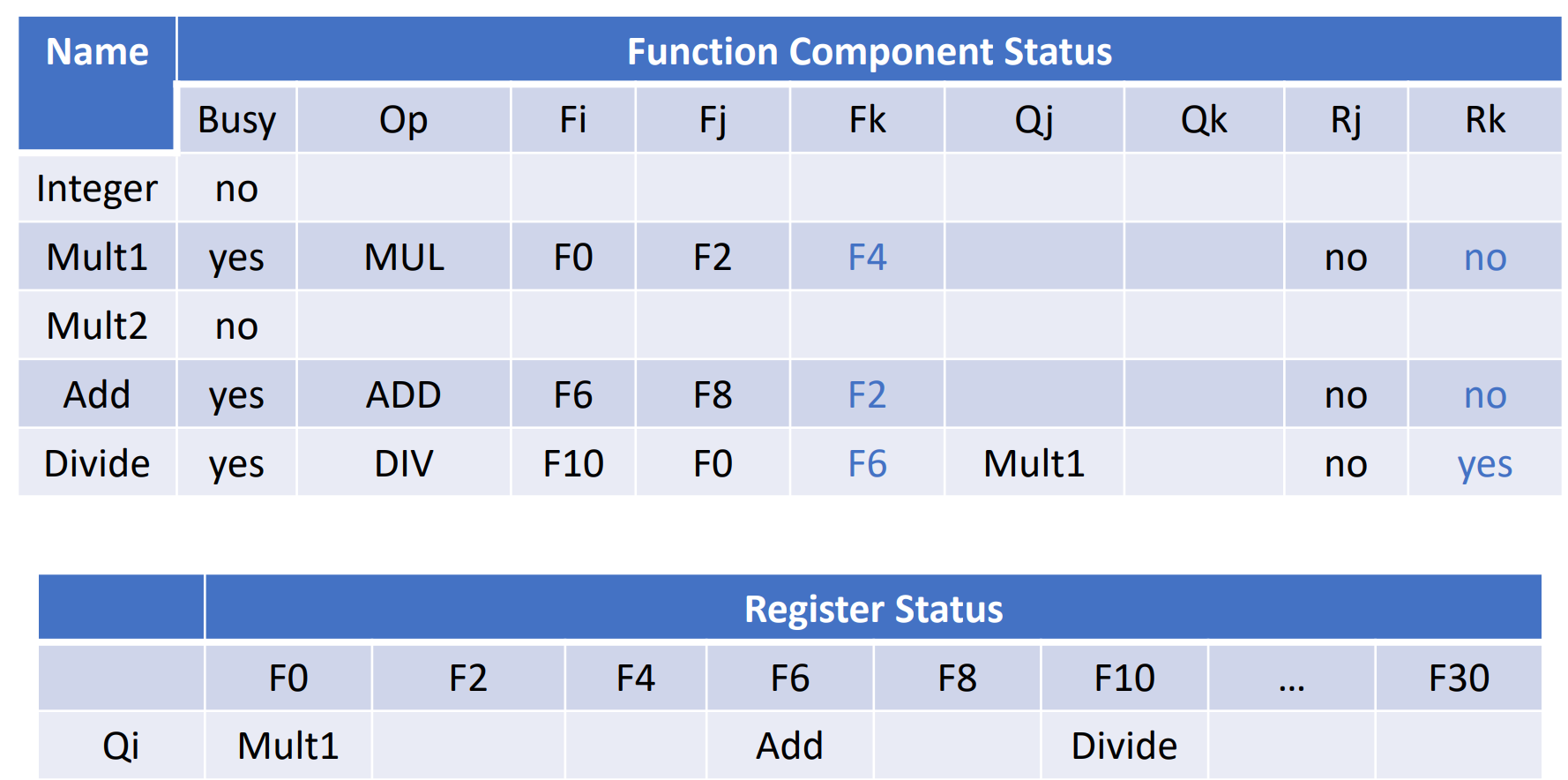
Tomasulo
每个部件前面有多个保留站(绿色),存储了要在这个部件上执行的指令,以及操作数的值。(这样避免WAR和WAW冒险,比如指令6要在指令5读R6之后才能写回)
IS: 从队列中 顺序 取出指令,并放入对应的保留站。进入保留站后,就会进行重命名,消除了 WAR 和 WAW 冒险
EX:
WB: 通过 CDB 总线将结果写回到寄存器的同时,将结果发到其他所有标记了的保留站里。(因此 CDB 也会影响 CPU 的效率,因此现在用多条总线保证效率)
Inst Status
跟scoreboard类似,IS、EX、WB三个阶段。只是为了理解算法,实际上硬件里没有。
Reservation Station Status
- Op
- Qj,Qk: 源操作数的值来自的保留站 (有依赖)
- Vj,Vk: 源操作数的值 (进入保留站时,把寄存器的值读出来并放到保留站中,这样其他指令写回就不影响了)
- Busy: 是否有指令占用
- A: Load/Store的目标地址
FLD F6, 34(R2)
FLD F2, 45(R3)
FMUL.D F0, F2, F4
FSUB.D F8, F2, F6
FDIV.D F10, F0, F60,,,,,
FADD.D F6, F8, F2
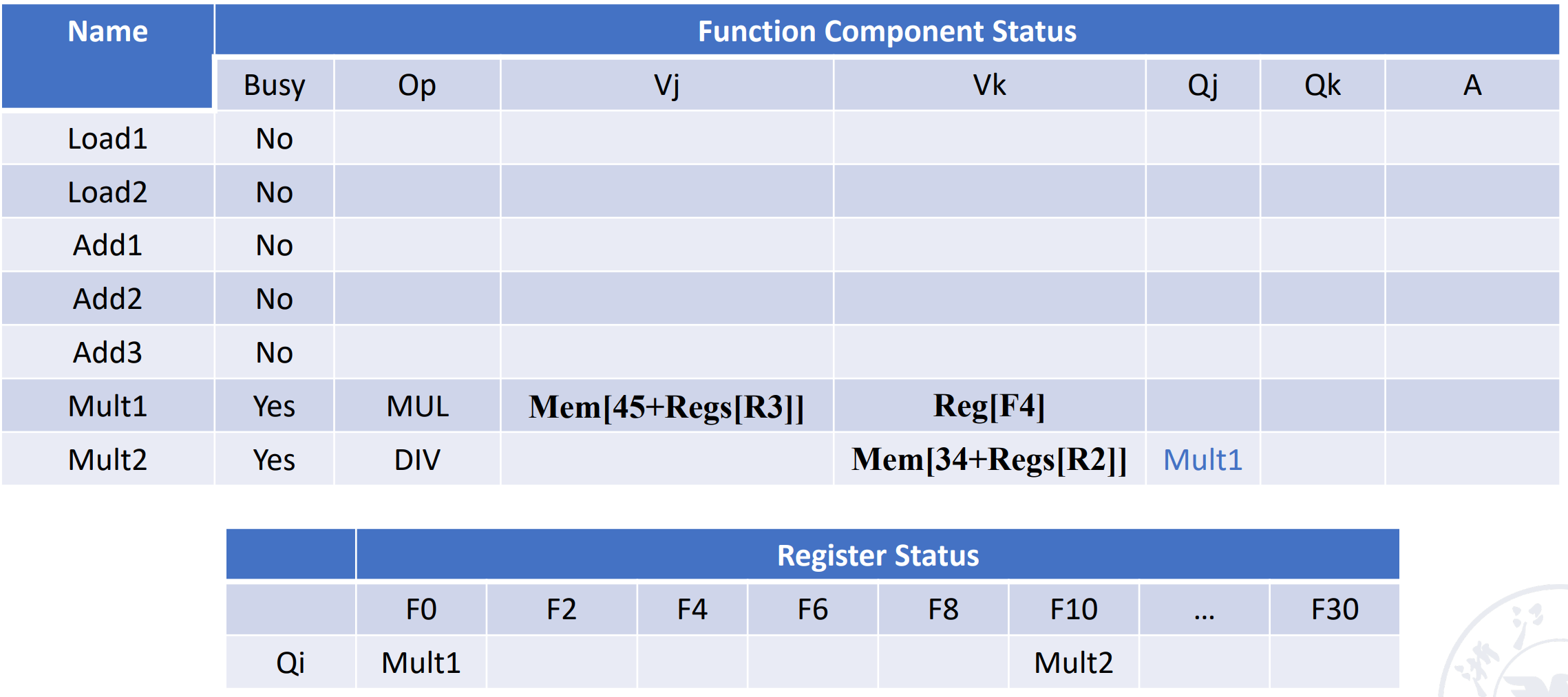
 Load2(FLD F2, 45(R3) ) 只有地址
Add1(SUB F8,F2,F6) Vk是F6已经WB了,所以Vk的值是已知的。 而Vj需要等F2的结果,依赖Load2
Mult1 F2依赖Load2 F4已知
Mult2 进入保留站的时候F6已经读了出来并放在Vk中, F0依赖Mult1
Load2(FLD F2, 45(R3) ) 只有地址
Add1(SUB F8,F2,F6) Vk是F6已经WB了,所以Vk的值是已知的。 而Vj需要等F2的结果,依赖Load2
Mult1 F2依赖Load2 F4已知
Mult2 进入保留站的时候F6已经读了出来并放在Vk中, F0依赖Mult1
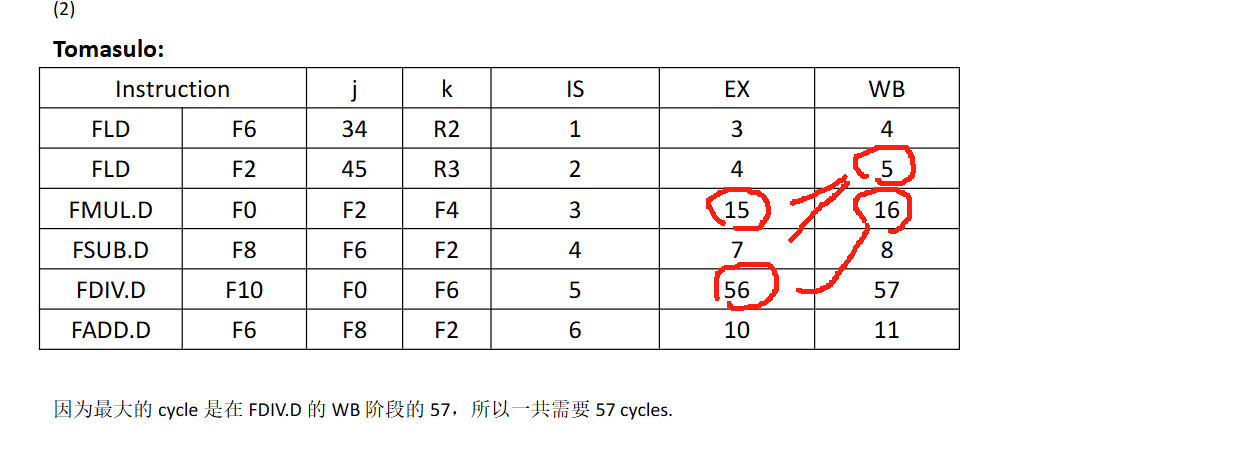
当第二条指令执行完。SUB和ADD结束了,只有5 DIV在等3 MUL
在指令 5 进入保留站的时候,F6 的值已经读出来并且放到了保留站中,此时无论指令 6 什么时候执行完,写回 F6 的值,都不会影响指令 5 的操作数
Hardware-base speculation
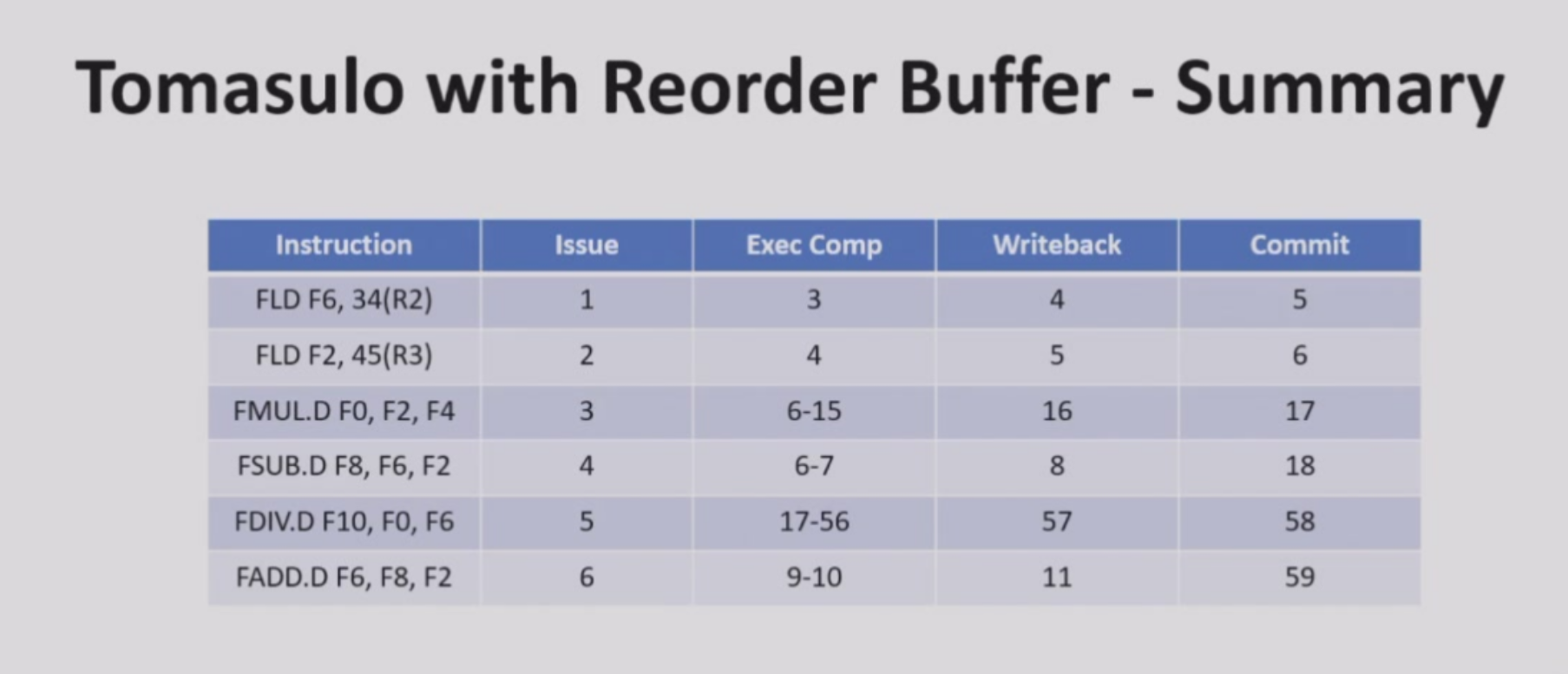
在tomasulo后加一行
- WB阶段把结果写入ROB. ROB 是指令操作数的来源,就像 Tomasulo 算法中的保留站提供操作数一样
- Commit阶段把结果写入寄存器组。必须按顺序提交
| IS | EX | WB | Commit | |
|---|---|---|---|---|
| FLD F6,34,R2 | 1 | 2-3 | 4 | 5 |
| FLD F2,45,R3 | 2 | 3-4 | 5 | 6 |
| FMUL.D F0,F2,F4 | 3 | 6-15 | 16 | 17 |
| SUB F8,F6,F2 | 4 | 6-7 | 8 | 18 |
| DIV F10,F0,F6 | 5 | 17-56 | 57 | 58 |
| ADD F6,F8,F2 | 6 | 9-10 | 11 | 59 |
超标量和VLIW
见98笔记
分支预测
2-bit branch predictor
2-level predictor
(m,n) branch predictor: Branch predictor - Wikipedia
- 对于一条指令,维护他最近m次的历史分支结果(跳转/不跳转) (01串)
- 预测表: 包含\(2^m\)个条目, 每个条目是一个n位的状态机(如果n=2就是2-bit branch predictor)
- 利用历史分支结果 查预测表中的条目,根据状态机预测
为每条分支指令维护一个预测表代价太大。只维护一个表,用{ m位分支历史, 指令地址的低k位 }来索引, 每个条目同样是一个n位状态机。
预测表总bit数 = \(2^m\times n\times\) 指令地址选择的数量